TDM 19 : Appréhender la mémoire pour éclairer le bas niveau
Posté le 16/12/2020 18:27
Le Tutoriel du Mercredi (TDM) est une idée proposée par Ne0tux, qui recouvre tous les usages de la calculatrice - des applications de Casio à la conception de jeux en passant par la production artistique.
Aujourd'hui, on explique le fonctionnement des add-ins par leur plus importante ressource : la mémoire !
Ce tutoriel fait partie des publications de l'Avent 2020.
Niveau ★ ★ ★ ★ ☆
Tags : Données, Mémoire, Pointeurs, C
Bienvenue à tous ! Ce tutoriel explique le fonctionnement de la mémoire à la façon des ordinateurs modernes, et en particulier de nos calculatrices. Il vous aidera à comprendre plus profondément les enjeux des add-ins et le fonctionnement du langage C.
Certaines notions abordées ici sont plus compliquées que d'autres, j'ai donc séparé le contenu en deux parties avec d'abord les choses plus faciles et ensuite les questions plus techniques. Je suis persuadé que tout le monde peut comprendre avec la bonne présentation et les bons schémas, donc n'hésitez pas à attaquer même les notions qui paraissent intimidantes !

C'est moralement une suite au
TDM 18, même s'il n'y a pas du tout besoin d'avoir lu le TDM 18 pour comprendre, j'y ferai simplement référence de temps en temps.
 Première partie (plus facile)
Première partie (plus facile)
•
La mémoire : l'espace dans lequel un programme s'exécute
•
La mémoire adressable
•
Pointeurs et tailles d'accès
•
Les classiques du C : segment de données, pile, et tas
•
Tour rapide des caches
•
La mémoire vue par le noyau de la calculatrice : des régions variées
•
L'importance de la mémoire en C
Deuxième partie (plus technique)
•
Quelques objets non adressables : registres périphériques
•
La mémoire virtuelle : agencer et protéger l'espace d'adressage
•
Optimiser des add-ins en utilisant mieux la mémoire
•
Conclusion
La mémoire : l'espace dans lequel un programme s'exécute
Une façon pertinente de comprendre la mémoire est de simplement la voir comme
l'espace où vit un programme. Surtout sur la calculatrice où il y a peu d'autres ressources, vous pouvez simplement considérer la mémoire et les ressources de calcul comme l'espace et le temps de votre programme (respectivement).
Ce qu'il faut comprendre en particulier c'est que la mémoire c'est une partie du matériel de l'ordinateur ou de la calculatrice. La mémoire précède le programme, elle existe avant que le programme soit lancé et continue d'exister après qu'il se soit terminé. Le programme n'est que l'exploitant temporaire d'une partie de mémoire qui lui est prêtée par le noyau du système d'exploitation.
Si on appelle la mémoire comme ça, c'est parce qu'elle sert à retenir des
données dans le temps. On peut y écrire des informations puis revenir les lire plus tard sans qu'elles aient changé. Les informations que l'on peut écrire, les « données », ne sont que des suites de 0 et de 1, car c'est la seule chose qu'un ordinateur sait manipuler.
Il est important de comprendre qu'il existe des données de plein de types différents : des nombres entiers, des nombres décimaux, du texte, des images... chaque type a sa propre façon de représenter les données sous forme de 0 et de 1. Mais la mémoire ne retient que les 0 et les 1, pas le type. Il est très facile de trouver des données de types différents qui se représentes avec la même séquence de bits. Par conséquent, pour pouvoir utiliser des données qui sont stockées dans la mémoire, il ne suffit pas d'aller lire ses bits, il faut aussi connaître leur type. Le
TDM 18 explique cela plus en détail et présente la façon dont les types de données courants sont représentés en binaire.
Pour des raisons historiques, on ne compte quasiment jamais les bits à l'unité, on les groupe par 8 en ce qu'on appelle des « octets ». Par exemple quand on 8 Go de RAM dans un ordinateur, c'est 8 Giga-octets, soit 8×8 = 64 milliards de bits.
Par ailleurs, pour faciliter la lecture, quand on écrit des longues séquences de bits on les groupe par 4 dans un format qu'on appelle « hexadécimal ». Chaque séquence de 4 bits est abrégée par un chiffre entre 0 et 9 ou une lettre entre a et f, de la façon notée dans la table ci-dessous.

Pour ce tutoriel il n'y a pas besoin de comprendre l'hexadécimal en détail, il faut surtout se souvenir que deux caractères hexadécimaux à la suite, par exemple
7b, ça fait un octet.
Avec cette introduction, nous voilà prêts à attaquer le coeur de la discussion !
La mémoire adressable
On sait donc que la mémoire c'est un bout de matériel qui retient la valeur d'une quantité fixe d'octets, comme une armoire dans laquelle on peut ranger des objets. Par exemple, la mémoire RS sur ma Graph 35+E II retient la valeur de 2048 octets (on dit que sa taille est 2048 octets). Un jour j'en ai fait une copie dans un add-in, et j'ai trouvé les valeurs suivantes stockées dans les 24 premiers octets.
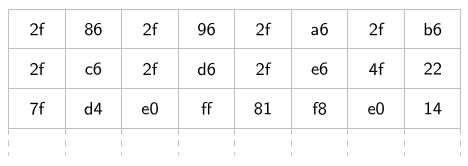
Ce sont toujours bien des bits ; par exemple le 3ème colonne de la 2ème ligne contient « 2f », ce qui est la notation courte pour la séquence de 8 bits 00101111. Mais à partir de ce moment-là, on commence à voir les octets comme des atomes indivisibles, c'est pour ça que ce tutoriel ne parle toujours que d'octets.
Toutes les cases de ce tableau sont un peu comme les tiroirs d'une armoire, il y en a un nombre fixe (la taille de la mémoire) et on peut les ouvrir pour voir ce qu'il y a dedans (
lire un octet) ou remplacer leurs contenus (
écrire un octet). Mais pour ça, il faut encore avoir un moyen de désigner ces cases.
Le principe de la
mémoire adressable est simplement de numéroter les cases une par une en commençant à 0. On appelle les numéros des cases des
adresses. Si j'ajoute les adresses sur le schéma précédent, ça donne ça :
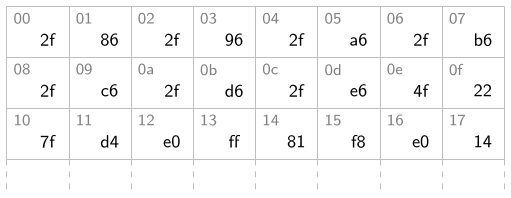
On écrit les adresses en hexadécimal pour des raisons que je discuterai après (alignment et adressage virtuel).
Les opérations que l'on peut faire sont donc
lire et écrire des octets à des adresses.
• Par exemple, si je lis l'octet à l'adresse 14, j'obtiens 81.
• Si j'écris à l'adresse 14 la valeur 3c, la mémoire devient comme ceci.
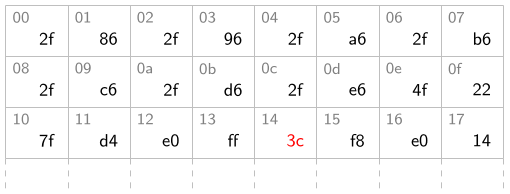
• Et dans ce cas, si plus tard je lis l'octet à l'adresse 14, j'obtiendrai 3c. L'ancienne valeur est perdue dès que j'écris.
Pointeurs et tailles d'accès
Si vous avez déjà programmé en C, vous avez sûrement entendu parler des
pointeurs. Selon la personne qui en parle les descriptions vont d'une fonctionnalité intriquée qui hantera vos cauchemars à un outil fondamental et polyvalent du langage.

Un pointeur c'est en fait simplement une adresse mémoire. Dans l'exemple précédent, j'ai fait mes lectures et écritures à l'adresse 14. Dans un programme C, je peux faire ces opérations à l'aide d'un pointeur contenant la valeur 14.
uint8_t *ptr = (uint8_t *)0x14;
// Lecture de la valeur initiale
int valeur_initiale = *ptr; // = 0x81
// Écriture de la nouvelle valeur
*ptr = 0x3c;
// Lecture de la nouvelle valeur;
int nouvelle_valeur = *ptr; // = 0x3c
Les 0x partout sont la notation qu'il faut utiliser en C pour écrire une valeur en hexadécimal. Vous remarquerez que j'ai créé un pointeur de type
uint8_t *, c'est-à-dire un pointeur vers une valeur de type
uint8_t dans la mémoire. C'est parce que je voulais lire et écrire un seul octet et donc j'ai pris un type dont la taille est 1 octet.
Car en fait la mémoire et le processeur sont capables de se mettre d'accord pour lire ou écrire plusieurs octets en même temps. Sur la calculatrice, on peut lire ou écrire 1, 2, ou 4 octets consécutifs d'un coup selon les besoins. On appelle chaque opération un
accès mémoire et le temps que ça prend est le même peu importe laquelle de ces trois tailles on choisit.

C'est important parce que beaucoup de variables font plus qu'un octet et c'est important pour les performances de ne pas avoir à faire 4 accès mémoire pour modifier la valeur d'un int. Parfois, quand on veut modifier énormément de mémoire d'un coup (par exemple pour effacer l'écran sur Graph 90+E), utiliser des accès de 4 octets permet aussi d'aller plus vite en réduisant le nombre d'accès mémoire.
Note supplémentaire.
En C, on peut aussi lire et écrire via des pointeurs vers des types plus gros comme des structures. Mais dans ce cas le compilateur décompose les accès en plusieurs instructions ou utilise des fonctions comme
memcpy(). La mémoire ne voit vraiment arriver que des accès de 1, 2 et 4 octets.
Accès alignés
Il y a quand même une limitation : on ne peut pas lire n'importe quels 2 octets ou n'importe quel 4 octets d'un coup. Il faut que le groupe soit
aligné :
• Pour pouvoir lire 2 octets, il faut que l'adresse soit un multiple de 2 (en anglais,
"2-aligned") ;
• Pour pouvoir lire 4 octets, il faut que l'adresse soit un multiple de 4 (en anglais,
"4-aligned").
Dans l'exemple précédent, je peux lire 4 octets à l'adresse 08 (ce qui donne 2f c6 2f d6), mais je en peux pas lire 4 octets à l'adresse 12 (qui n'est pas un muliple de 4 — on se rappelle que les adresse sont écrites en hexadécimal, et 0x12 = 18). Par contre je peux lire 2 octets à l'adresse 12, j'obtiendrai e0 ff.

Dans un add-in créé avec le fx-9860G SDK ou le Prizm SDK, une System ERROR avec le message "
ADDRESS(R)" ou "
ADDRESS(W)" se produit si vous tentez de faire un accès mémoire avec une adresse qui n'est pas un multiple de la taille de l'accès. gint affiche un message du genre "Read/Write address error". En général ça veut dire que vous avez fait passer un pointeur d'un certain type pour un pointeur d'un autre type et que l'alignement n'est pas bon.
Maintenant que vous savez ce que la mémoire contient et comment on y accède, voyons le rôle qu'elle occupe dans un programme.
Les classiques du C : segment de données, pile, et tas
Lorsqu'on exécute un programme (peu importe le langage), le noyau lui prête de la mémoire de trois façons différentes.
Segment de données
Le noyau prête de la mémoire au programme une première fois lorsqu'il charge son code et ses données. Le code est chargé en lecture seule (les accès en écriture sont refusés, et provoquent des System ERROR ou ne font rien selon les cas), tandis que les données sont en lecture-écriture. En C, les variables globales et statiques sont chargées à ce moment-là.
int global_x = 2; // Se situe dans le segment de données
int get_counter() {
static int counter = 0; // Se situe dans le segment de données
return ++counter;
}
Le segment de données a une taille fixe au moment où le programme est compilé (c'est la taille occupée par toutes les variables statiques et globales combinées, essentiellement) et ne change pas au cours de l'exécution.
Pile
La pile est une région de mémoire utilisée pour stocker les variables locales des fonctions. C'est une
pile au sens algorithmique du terme. Chaque fonction en cours d'appel y stocke ses variables locales, et chaque sous-fonction empile ses variables par-dessus celles de sa fonction parente.
La région attribuée par le noyau pour stocker la pile peut être de taille fixe (comme sur la calculatrice) ou de taille variable (comme sous Linux). En général il y a une limite de taille. Lorsqu'une fonction démarre, elle stocke automatiquement ses variables locales au sommet de la pile, et lorsqu'elle s'arrête, elle libère la place en retirant ses variables.
Le code qui place les variables sur la pile ne vérifie pas s'il y reste assez de place. Il y a plusieurs raisons pour ça, mais en gros (1) il n'y a pas de façon simple de savoir s'il reste de la place, et (2) vu le nombre de fonctions qu'on lance ça prendrait beaucoup trop de temps. Si une fonction arrive au bout de la pile, un erreur qu'on appelle « dépassement de pile » (ou
"stack overflow" en anglais) se produit. Selon les cas, ça peut être une segfault, une System ERROR, voire encore pire (sur la calculatrice ça écrase les données de quelqu'un d'autre sans renvoyer d'erreur).
Pour cette raison, la pile est vraiment pensée juste pour les petites variables locales, et ce n'est jamais une bonne idée d'y mettre des grandes variables comme des tableaux de plusieurs milliers d'éléments.
int triple(int x) { // x se situe sur la pile
int t = x + x + x; // Se situe sur la pile
return t;
}
Tas
Le tas est la troisième et dernière région classique que le noyau attribue au programme. Quand Firefox consomme 4 Go de votre précieuse RAM c'est (en très très gros) ici que ça se passe. Le programme peut demander au noyau d'agrandir ou réduire son tas à tout moment (sauf si le noyau refuse bien sûr). À l'origine, le tas est juste un gros paquet de mémoire, et le programme peut mettre des variables un peu où il veut dedans.
Le tas est utile dans trois situations :
1. Pour stocker des très grosses données.
2. Pour stocker des données d'une taille variable qu'on ne connaît pas à la compilation.
3. Pour créer des variables qui continuent d'exister quand une fonction termine.
Dans toutes ces situations, on utilise normalement une fonction de la bibliothèque standard du C qui s'appelle
malloc(). Le rôle de
malloc() est de trouver quelque part dans le tas de la place pour créer une variable de la taille dont vous avez besoin, et si ce n'est pas possible de demander au noyau plus de tas pour que ça le devienne. C'est une tâche plus difficile que ça en a l'air car le tas se remplit avec le temps de variables créées au fur et à mesure du programme et peut presque devenir un champ de mines.
Je ne voudrais pas rentrer dans les détails de l'allocation dynamique, mais comme je sais que c'est un sujet difficile à aborder voici quelques précisions.
malloc() prend un seul paramètre qui est la taille de la variable qu'on veut créer. Elle renvoie un pointeur qui désigne l'adresse du tas où la place a été réservée. Dans le cas 1, on pourra par exemple écrire :
uint8_t *tableau_de_10000_octets = malloc(10000);
/* ... */
free(tableau_de_10000_octets);
malloc() se charge de trouver 10'000 octets consécutifs dans le tas qui ne sont pas déjà utilisés, et renvoie leur adresse (ou
NULL si le tas est plein et que le noyau ne veut plus nous donner de mémoire). Lorsqu'on a fini d'utiliser la variable, il faut signaler à
malloc() que la place est libre pour d'autres variables, c'est ce qu'on fait en appelant
free().
Dans le cas 2, on écrira par exemple :
int n = demander_un_nombre_a_lutilisateur();
uint8_t *tableau_de_n_octets = malloc(n);
/* ... */
free(tableau_de_n_octets);
Dans cette situation, on ne sait même pas combien d'octets on va vouloir allouer parce que la quantité dépend de ce que l'utilisateur choisit de saisir au clavier. Ça peut sembler très arbitraire, mais en réalité il y a énormément de cas comme ça dans la vie courante : la taille des fichiers, des chaînes de caractères, des listes...
On ne peut pas placer cette variable dans le segment de données parce que sa taille n'est pas connue à la compilation, et on ne peut pas non plus la placer sur la pile parce qu'elle risque d'être bien plus grande que la taille de la pile (sous Linux, la pile est souvent limitée à 8 Mo même si votre ordinateur a 16 Go de RAM ; tous les gros objets sont vraiment dans le tas).
Dans le cas 3, on écrira par exemple :
struct joueur *creer_joueur()
{
struct joueur *j = malloc(sizeof(struct joueur));
j->hp = 20;
j->mp = 10;
j->x = 0;
j->y = 0;
return j;
}
Ici on a une fonction dont le rôle est de créer un joueur. On pourrait créer une variable locale de type
struct joueur et la renvoyer, mais comme chaque fonction a une place différente dans la pile ça nous obligerait à la copier tout le temps. À la place, on peut simplement la créer dans le tas et renvoyer son adresse. La personne qui appelle
creer_joueur() ne doit pas oublier d'appeler
free() lorsqu'elle n'a plus besoin du joueur.
Je m'arrête là pour revenir sur la mémoire à proprement parler, mais si des choses vous échappent là-dedans vous pouvez toujours demander dans les commentaires.
Tour rapide des caches
Si vous cherchez des ordres de grandeurs pour comparer la performance de la RAM et des processeurs au cours du temps, vous allez vite voir qu'un problème se pose. Dans les débuts de l'informatique, les processeurs étaient lents et un accès à la RAM se faisait en un seul cycle du processeur (une instruction). Aujourd'hui, ce n'est plus du tout le cas car les processeurs ont progressé bien plus que la RAM.
Dans un ordinateur portable moyen, le CPU et la RAM sont éloignés de peut-être 5 centimètres. Traverser cette distance aller-retour en un cycle d'une horloge à 3 GHz demande tout juste d'aller à la vitesse de la lumière dans le vide. Le signal électrique va
très vite, mais il ne faut pas abuser (et surtout il faut laisser au CPU et à la RAM le temps de faire leur travail, un accès mémoire c'est plus compliqué qu'un aller-retour).
Aujourd'hui si on regarde la mémoire dans un ordinateur, il y a un compromis omniprésent entre la taille et la vitesse. Une grande mémoire prend de la place, donc il faut l'éloigner du processeur, et ultimement elle ira moins vite. Une mémoire rapide doit être près du processeur et on n'a donc pas la place de la faire très grande.
L'idée d'un cache est un compromis dans cette situation. Il s'agit d'une mémoire intermédiaire, de taille modeste, située entre le processeur et la RAM. Quand on accède à une adresse en RAM, les données lues ou écrites sont conservées dans le cache pendant quelques temps, comme ça si on effectue un autre accès à ces données elles seront déjà tout près et donc l'accès sera rapide. Si on brasse beaucoup de RAM le cache s'arrange pour retenir les données auxquelles ont a accédé le plus récemment, dans la limite de sa taille. Le programme ne se rend pas compte qu'un cache existe, les accès mémoire vont juste plus vite quand les données sont présentes dans le cache.
Ce concept est tellement efficace que le processeur x86 moyen aujourd'hui a une
hiérarchie de caches : un tout petit devant le processeur (L1), un plus gros un peu plus loin (L2), un autre encore un peu plus gros et encore un peu plus loin (L3), et ensuite seulement la RAM. Les programmes scientifiques consommateurs de ressources (par exemple les multiplications de matrices immenses) jouent très attentivement avec le cache pour maximiser leurs performances et c'est un énorme boost.
Sur la calculatrice il y a deux caches (sur SH4), ou parfois aucun (sur SH3). Les systèmes embarqués n'ont pas toujours de cache parce qu'au niveau électronique c'est super compliqué à réaliser (et c'est immonde sur les processeurs multi-coeurs). On a par contre un truc plus simple mais utile également, qui sont des petites régions de RAM rapide proches du processeur. C'est la même idée qu'un cache, mais les contenus sont indépendants de la RAM et un programme peut juste lire et écrire dedans à volonté.
La mémoire vue par le noyau de la calculatrice : des régions variées
La calculatrice est un système embarqué et donc assez minimaliste comparée à un ordinateur. Quasiment tout le matériel est sur la même puce (contrairement à un PC complet où le CPU, la RAM et les périphériques sont entièrement séparés). Il n'y a pas de disque dur ni de carte SD (sauf sur la Graph 95 SD), à la place l'OS et les fichiers sont stockés dans une ROM.
Depuis un programme, on veut pouvoir accéder à toute la mémoire de la calculatrice. Pour s'assurer que chaque région a des adresses uniques et éviter les ambiguités, on ajoute une « adresse de base » à chaque région. Par exemple, la RAM a une adresse de base égale à
88000000, et donc l'octet de position
1c dans la RAM a une « adresse absolue » de
8800001c. La mémoire RS a une adresse de base égale à
fd800000 et donc l'octet de position
1c dans la mémoire RS a une adresse absolue de
fd80001c.
Du coup, dans un programme, on peut facilement distinguer l'adresse
1c dans la RAM de l'adresse
1c dans la mémoire RS :
uint8_t *adresse_1c_RAM = (uint8_t *)0x8800001c; // pointe vers la RAM
uint8_t *adresse_1c_RS = (uint8_t *)0xfd80001c; // pointe vers la mémoire RS
Sur la calculatrice les pointeurs font 32 bits et donc la plage de valeurs disponibles va de
00000000 à
ffffffff. Si toutes ces adresses étaient utilisées ça ferait 4 Go de mémoire en tout. Clairement sur la calculatrice il y a beaucoup moins de mémoire que ça donc plein d'adresses absolues ne pointent nulle part.
uint8_t *le_vide = (uint8_t *)0xc6000000; // pointe vers rien du tout
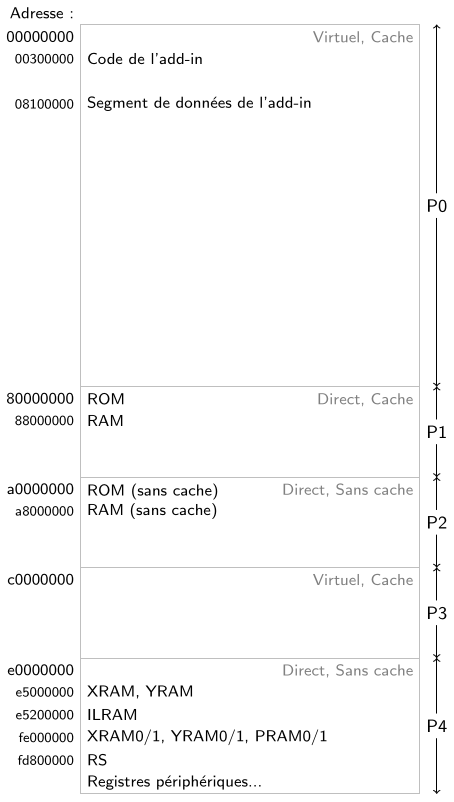
Voici une version simplifiée de la « carte de la mémoire », où chaque région majeure est affichée en face de son adresse absolue.

À part la ROM et les registres périphériques, tout ce qui se trouve dans cette carte est une forme de RAM. La RAM principale est la plus lente mais aussi la plus grosse. La XRAM et la YRAM sont liées au DSP et très rapides, l'ILRAM est toute petite mais rapide aussi. Les XRAM0/1, YRAM0/1 et PRAM0/1 sont liées aux
coprocesseurs DSP du SPU et sont assez grandes mais très tordues (on ne peut faire que des accès de 4 octets, et il y a des trous).
Le segment de données d'un add-in, sa pile et son tas sont tous dans la RAM principale au voisinage de l'adresse
88000000. L'OS n'utilise pas vraiment les régions de RAM rapides (sauf la mémoire RS qui contient du code critique permettant de redémarrer la calculatrice et enregistrer des fichiers, et que je vous conseille de ne jamais modifier).
Comme l'OS met toutes les données de l'add-in dans la RAM principale, pour utiliser les zones de mémoire rapides il faut utiliser explicitement l'adresse qui va bien :
int *tableau_de_10_int_dans_la_XRAM = (int *)0xe5007000;
double *double_XRAM = (double *)0xe5007024;
Ça pose quand même plsieurs soucis :
• D'abord on est obligés d'utiliser des pointeurs : il faut écrire
*double_XRAM = 1.5 et pas juste
double_XRAM = 1.5.
• Ensuite on ne peut pas initialiser facilement les contenus.
• Et le plus important : le programmeur doit choisir lui-même les adresses et ne pas se tromper en mettant par erreur deux variables à la même adresse. Ici par exemple je me suis trompé et le dernier élément du tableau intersecte le double, donc le programme ne marche pas du tout.
gint est capable de charger des données dans quasiment toutes les régions. Ça se fait en plaçant les données dans une section prédéfinie à l'aide d'une macro, le linker script traque ensuite chaque section pour que le loader copie les données au bon endroit. Pour la XRAM par exemple, on peut écrire :
#include <gint/defs/attributes.h>
GXRAM int tableau_de_10_int_dans_la_XRAM[10];
GXRAM double double_XRAM;
Ça revient au même, c'est juste plus facile à maintenir.
L'importance de la mémoire en C
La plupart des langages de haut niveau essaient de cacher l'existence de la mémoire comme un espace d'adressage, de la pile, et souvent presque du tas aussi. En fait le langage C cache déjà l'existence de la pile derrière l'usage de variables locales. Dans les langages de plus haut niveau comme en Python, on crée une variable et le langage gère le tas sans qu'on se pose de questions.
Avoir la gestion manuelle de la mémoire est un travail supplémentaire pour lequel il faut payer le coût de surveiller les
malloc() et de construire élégamment son programme pour s'assurer que chaque variable est libérée avec
free() une et une seule fois. Mais ce coût vient aussi avec la capacité de contrôler finement la consommation mémoire, la répartition des données, et l'usage de fonctionnalités matérielles comme les régions de mémoire rapide.
Le C est un langage bas niveau comparé à ce qu'on croise couramment (C++, Python, Java, Lua — choisissez votre préféré). Il vous donne fondamentalement plus de contrôle sur le matériel au prix de plus d'efforts de développement. Si vous écrivez un noyau, vous en serez ravis parce que vous avez besoin de ce contrôle pour accomplir les tâches du noyau et faire tourner les rouages les plus fins. Si vous écrivez un gros jeu, ça sera surtout du travail en plus et vous voudrez sans doute avoir un moteur de jeu qui crée l'abstraction. Dans le cas extrême, il faudrait même prendre un langage de plus haut niveau : tous les outils ne sont pas bons pour toutes les tâches, si le jeu est de haut niveau le langage doit l'être aussi. Malheureusement pour l'instant le C est la seule option viable pour les add-ins.
Quelle est donc l'importance de la mémoire en C ? C'est que la gestion de la mémoire est la frontière d'abstraction que le langage ne franchit pas. C'est une propriété assez unique parce que peu de langages couramment utilisés aujourd'hui prennent ce parti. Et c'est une fabuleuse porte ouverte pour découvrir ce qui se cache vraiment dans un ordinateur.
Quelques objets non adressables : registres périphériques
Jusqu'ici on a surtout parlé de mémoire adressable parce que c'est ce qu'il y a de plus gros et de plus utile. Mais l'espace d'adressage contient aussi des données qui ne sont pas de la mémoire adressable. L'exemple le plus frappant de ça est les
registres périphériques.
Essentiellement, les registres périphériques sont des variables (« registres ») présentées par les différents modules matériels sur la puce (appelés « modules périphériques » parce qu'ils sont autour du processeur et du bus). Ils font tous 1, 2 ou 4 octets et on peut lire ou écrire leur valeur en un seul accès mémoire.
Ils sont situés pour la plupart de façon plus ou moins organisée dans P4. Par exemple
fe2ffe18 est l'adresse d'un registre périphérique appelé CHCR2, de 4 octets, qui contrôle l'opération d'un des canaux DMA de (l'hypothétique) DSP0. On y accède avec un pointeur vers un type de 4 octets.
volatile uint32_t *SPU_DSP0_CHCR2 = (void *)0xfe2ffe18;
*SPU_DSP0_CHCR2; // ...
Ces registres ne sont pas de la mémoire adressable. D'ailleurs si on essaie lire un seul octet à l'adresse
fe2ffe18, on n'obtient pas du tout le premier octet de CHCR2, on obtient 0. Seul les accès d'exactement 4 octets ont du sens ici.
Ce n'est pas le seul endroit de ce type d'ailleurs, les XRAM0/1, YRAM0/1 et PRAM0/1 que j'ai mentionnées tout à l'heure ne supportent que les accès alignés de 4 octets, et dans certains cas seuls 3 des 4 octets sont vraiment de la mémoire. (C'est compliqué.)
Il peut y avoir plein d'objets étranges dans l'espace d'adressage quand on fait du bas niveau. Dans un OS plus haut niveau comme Linux (et notamment quand les programmes sont en userspace) c'est beaucoup plus simple, tout ce qu'on voit dans l'espace d'adressage du programme c'est le code, la pile et le tas (plus les pages allouées directement avec
mmap(), ce qui fonctionne à peu près comme le tas), c'est tout de la mémoire adressable, et on se pose pas de questions.
La mémoire virtuelle : agencer et protéger l'espace d'adressage
Ce qui m'amène tout naturellement au prochain sujet : la mémoire virtuelle. Cette chose est vraiment vaste et mérite des chapitres entiers à elle toute seule, qu'elle a d'ailleurs déjà dans tout bon livre de systèmes d'exploitation. Pour l'instant je vais faire court et simplement compléter le diagramme simplifié de l'espace d'adressage que je vous ai montré tout à l'heure pour y intégrer les zones virtuelles P0 et P3.
Pour comprendre l'intérêt de la mémoire virtuelle, il faut remarquer que l'espace d'adressage est « souple » : on peut faire un peu ce qu'on veut avec. Le processeur peut intercepter les adresses et faire des ajustements avant d'accéder à la mémoire.
Par exemple, dans certaines situations on veut être capables de contourner le cache et forcer le processeur à accéder à la RAM ou à la ROM même si le cache est allumé et que les données auxquelles on accède sont dedans. Pour cette raison, il y a deux adresses différentes pour la ROM :
80000000 (dans P1) et
a0000000 (dans P2). Si on utilise l'adresse P2, le processeur s'en rend compte et ignore le cache. Pareil pour la RAM.
Le principe de la mémoire virtuelle c'est de modifier à la volée la façon dont l'espace d'adressage est agencé. Par exemple, quand vous cliquez pour lancer un add-in dans le menu principal, l'OS de la calculatrice modifie l'agencement de P0 pour faire pointer
00300000 vers le secteur de la ROM qui contient l'add-in (le fichier g1a ou g3a). Il fait aussi de la place en RAM pour charger le segment de données de l'add-in et fait pointer
08100000 vers cet endroit.
Ça a énormément d'avantages, mais je vais simplement donner les grandes idées ici.
Userspace. Grâce à la mémoire virtuelle, l'OS est capable de créer l'illusion que l'add-in est toujours à l'adresse
00300000, alors que sa position réelle en ROM dépend de ce qu'il y a dans la mémoire de stockage et change presque à chaque fois qu'on transfère le fichier. C'est le premier pas vers ce qu'on appelle le "userspace" ou « espace utilisateur », qui consiste à donner à chaque programme son propre espace d'adressage avec son code et ses données à une adresse fixe. Si on pouvait lancer deux add-ins en même temps, ils auraient chacun un agencement différent de P0 qui leur donnerait l'impression d'être tous les deux dans la mémoire à l'adresse
00300000 tout en étant tous les deux dans la ROM.
Sécurité. Par extension, on peut virer de l'espace d'adressage d'un programme toute la mémoire à laquelle il n'est pas supposé accéder. En mode utilisateur, seul P0 est accessible : P1, P2, P3 et P4 sont réservés au noyau. Mais par chance pour nous les add-ins ne sont pas exécutés en mode utilisateur sur la calculatrice (ce qui est un peu « négligent » de la part de l'OS), ce qui nous permet de jouer avec la mémoire et le matériel.
Continuité. La mémoire virtuelle est découpée en blocs appelés « pages » qui sont tous indépendants les uns des autres. En particulier, la page à
00300000 peut pointer vers un secteur au tout début de la ROM et la page suivante vers un secteur tout à la fin. Ce qui est super important parce que les fichiers dans la mémoire de stockage sont fragmentés (ils sont stockés par morceaux pas les uns à la suite des autres), et donc sans l'aide de la mémoire virtuelle on ne pourrait même pas savoir facilement où le code de l'add-in est dans la mémoire !
Le procédé de déterminer où une adresse virtuelle comme
00300000 mène s'appelle la « traduction d'adresses » et est accompli par un module du processeur qui s'appelle le MMU ("Memory Management Unit"). C'est un terme que vous m'avez peut-être déjà vu employer.
Optimiser des add-ins en utilisant mieux la mémoire
L'utilisation de la mémoire représente traditionnellement un point de blocage sur les performances plus vite que l'utilisation des ressources de calcul. Surtout sur Prizm et Graph 90+E où chaque image à afficher à l'écran contient 170'000 octets de couleurs, et où quasiment tout dessin devient un problème de performances.
Il n'y a pas des milliers de façons d'optimiser un programme, mais en voici trois qui exploitent au mieux la mémoire. Ce ne sont pas les trois premières choses à faire pour optimiser un programme, mais ce sont trois choses importantes à tenter si les accès à la mémoire sont la source de vos problèmes.
1. Réduire la taille des structures de données
Utiliser moins de mémoire est une façon évidente de passer moins de temps à y accéder. Les caches renforcent cet effet parce que si les données importantes sont assez petites pour tenir dans le cache, les accès iront beaucoup plus vite.
La majorité de la consommation mémoire d'un add-in se situe dans les gros tableaux. La liste des objets à l'écran, la map 2D du monde, le texte complet du fichier en cours d'édition... sont des examples de gros tableaux qu'on rencontre couramment. Le premier réflexe est de déterminer si les éléments du tableau peuvent être plus petits. Par exemple, si j'ai moins de 65'000 tiles dans mon monde (ce qui est le cas), les éléments de la map peuvent être des
uint16_t (de 2 octets chacun) au lieu de
int (de 4 octets chacun), divisant par deux le poids de la map en mémoire.
Je conseille de toujours réfléchir à cette question quand on crée des gros tableaux voire même quand on prépare le programme au papier, parce que ça a un impact vraiment important sur les ressources. Parfois vous réaliserez que votre concept d'un monde quasi-infini ne tient pas en mémoire et ça vous emmènera dans la bonne direction pour structurer votre moteur.
2. Utiliser les régions de mémoire rapide
Les régions de mémoire rapide sont petites mais peuvent s'avérer très utiles si vous avez des données utilisées couramment qui ne tiennent pas dans le cache ou doivent rester accessibles à tout instant. Vous pouvez notamment utiliser l'ILRAM (4 ko), la XRAM (8 ko) et la YRAM (8 ko) sans vous poser de questions. Les autres régions sont plus compliquées à exploiter.
Le gain en performance n'est pas garanti donc soyez sûr·e d'accompagner ces optimisations de benchmarks pour vérifier leur impact réel sur la fluidité du programme.
3. Utiliser le DMA
Je n'en ai pas parlé ici par manque de place, mais il existe un module périphérique appelé DMA dont la seule et unique tâche est de copier de la mémoire (entre différentes régions et parfois même avec des périphériques) pendant que le processeur fait autre chose. Le degré de parallélisme entre le processeur et le DMA est une question compliquée qui dépend de beaucoup de facteurs, mais en gros le processeur peut faire des calculs en même temps que le DMA copie de la mémoire.
Ce mécanisme est notamment utilisé pour envoyer la VRAM à l'écran à chaque nouvelle image, que ce soit par
Bdisp_PutDisp_DD() (PrizmSDK) ou
dupdate() (gint). Sans le DMA, ce serait impossible de maintenir même 30 FPS sur un add-in !
C'est assez facile d'utiliser le DMA dans le code mais un peu sensible de mesurer et valider le gain de performances que ça apporte, donc là aussi munissez-vous de benchmarks si vous voulez tenter cette approche pour optimiser votre add-in.
Conclusion
La mémoire est l'espace dans lequel un programme et ses données évoluent. Sur une plateforme embarquée comme la calculatrice, la mémoire joue un rôle très important dans la maîtrise de ce que fait un add-in.
Contrairement à la majorité des langages, qui est de plus haut niveau, le C laisse au programmeur la liberté et la responsabilité de gérer l'utilisation de la mémoire. Certains programmes n'en feront qu'un usage routinier tandis que d'autres iront en tirer jusqu'aux ultimes bénéfices de structure et de performance.
Sur une plateforme moderne avec un espace utilisateur comme Linux, l'usage de la mémoire est beaucoup plus répétitif, et les langages de plus haut niveau en abstraient la gestion car l'immense majorité des programmes ne se soucie pas des fins détails.
J'espère que ce tutoriel (presque aussi long que le précédent) vous aura éclairé sur l'arrière-boutique des programmes un peu mystiques que sont les add-ins. Le sujet est toujours bien plus vaste que ce qu'on peut en dire dans un seul article, donc n'hésitez pas à apporter vos questions et remarques dans les commentaires. o/
Et à bientôt sur Planète Casio !
Consulter le TDM précédent :
TDM 18 : Comprendre les données et leurs représentations
Consulter l'ensemble des TDM


Citer : Posté le 16/12/2020 18:52 | #
Tellement clair tout ça !
j'vais pas vous cacher que j'ai pas tout compris, mais ça c'est juste que je connais pas vraiment ce monde, mais le TDM est vraiment bien expliqué.
Promis, je le relirai quand j'aurais la tête un peu plus libre, faut pas que je loupe un truc de cette qualité
Lephe', ça te dirais de ne jamais arrêter ce genre de tutos ?
Citer : Posté le 16/12/2020 19:55 | #
Merci beaucoup pour tes tutos, Lephé
P.S: je lirais ça demain, il est tard ici
Tu veux pas écrire un livre sur le computer science au final ?
Passé ici il y a peu. ಥ‿ಥ
Jouez à Mario sans arrêt sur votre Casio !
City Heroes
Piano Casio
Micro GIMP
Citer : Posté le 16/12/2020 20:06 | #
Merci pour ces retours ! Qu'est-ce qui vous a paru plus clair ou plus obscur dans le paquet ? C'est un sujet non trivial, je doute que mes explications soient claires partout pour quelqu'un qui ne connaîtrait pas.
Lephe', ça te dirais de ne jamais arrêter ce genre de tutos ?
Ah c'est gentil ça, merci. <3 Je veux bien en faire plus mais faut isoler les sujets, si c'est « juste » pour traiter de C il y a déjà plein de bons tutos dans la nature. Si vous pouvez m'aider à localiser les problèmes classiques liés à la calculatrice... je peux continuer.
Tu veux pas écrire un livre sur le computer science au final ?
Ce serait un boulot d'une tout autre envergure.
Citer : Posté le 27/12/2020 10:10 | #
MA-GI-STRAL !
Bravo pour ce nouveau tuto très bien écrit et très instructif. Pour ma part j'ai beaucoup appris sur les caches (je n'avais pas connaissance de leur multiplicité ni gradation) et sur la cartographie mémoire.
A ce sujet, la cartographie n'est probablement pas une information donnée dans le manuel des CASIO donc comment a-t-elle été déterminée ? Est-ce une combinaison des Datasheet CPU/RAM, un travail de retro-ingeneering, le fruit d'essai/erreur ? Je trouve ça très intéressant comme connaissance car ça décuple le "contrôle" dont tu parles pour les langages bas-niveau.
Ceci dit, mon ressenti est que le systèmes actuels ont tendance à embarquer plus de ressources que nécessaires pour éviter aux développeurs de rentrer dans ce niveau de détail pour parvenir à faire tourner leurs applications. Les calculatrices sont un beau contre exemple.
Tu parles plusieurs fois de benchmarks et je me demandais : gint embarque-t-il un profiler ? C'est en effet un prérequis à toute entreprise d'optimisation.
Merci encore pour la rédaction. A titre indicatif j'ai bien mis 40 minutes à lire l'article.
La Planète Casio est accueillante : n'hésite pas à t'inscrire pour laisser un message ou partager tes créations !
Citer : Posté le 27/12/2020 10:20 | #
libprof is the official profiling library for gint
Citer : Posté le 27/12/2020 18:21 | #
Wow, merci beaucoup ! Tant de retours positifs !
En effet, les add-ins ont accès à toutes ces merveilles qui ne sont pas du tout triviales à trouver. La base est le manuel du SH7724, qui ressemble au MPU embarqué sur la calculatrice. Lire la doc du SH7724 permet de poser très fermement le cadre : quel genre de ressources il y a (modules et registres périphériques), comment ils communiquent (bus), comment ils interagissent avec le CPU, etc.
À partir de la doc, on peut comprendre quels objets sont importants (genre le DMA) et comment les utiliser. Le SH7305 (le vrai qui est dans la calculatrice) ne fonctionne pas toujours pareil et pour avoir le vrai comportement c'est un mélange de test intensif, de lecture de la doc existante comme celle de Simlo, et de désassemblage du noyau de l'OS.
Bien sûr tout ce qui est dans le SH7724 n'est pas dans la calculatrice, énormément de modules média (traitement d'images/son/vidéo) n'y sont pas. D'autres modules y sont mais ne sont documentés nulle part, et c'est le cas des coprocesseurs DSP d'où on tire les XRAM0/1, YRAM0/1 et PRAM0/1. De loin le plus dur, ça c'est reverse-engineering de l'émulateur et aussi beaucoup de tests.
Dans l'ensemble pour la cartographie de la mémoire adressable, l'information provient à 75% la doc du SH7724, 15% reverse-engineering de l'émulateur, 10% de tests machines et un peu de désassemblage de l'OS à vue de nez.
Le but de gint est aussi de donner un accès simple et unifié à toutes ces mécaniques pour sortir le maximum du maximum de puissance. (Comme ça les gens téléchargent mes jeux et mes libs.
Pour le profiler il y a libprof en effet, en général on s'en sert pour mesurer le temps d'une fonction ("one-shot") mais cette lib supporte du "profiling" à proprement parler où elle comptabilise le temps total passé dans chaque fonction et sous-fonction, pourvu que tu instrumentalises ton programme à la main (tu dois insérer du code dans chaque fonction qui fait des mesures, c'est pas automatique comme le ferait gprof avec l'aide du compilo par exemple).
Enfin, suivant ma philosophie de « présenter l'information complètement et densément », j'ai implémenté dans gintctl un nombre décent (et grandissant) de tests de performances, comparant par exemple les façons d'implémenter memcpy() le plus rapidement selon les zones de mémoire.
Citer : Posté le 28/12/2020 23:26 | #
Merci beaucoup pour toutes ces explication Lephé. J'ai appris pas mal de choses, notamment autour des mémoires caches.
L'utilisation des mémoires rapides XRAM, YRAM et PRAM est intéressant, je pense qu'en pratique, il y a des choses que je pourrai améliorer dans Windmill. J'ai atteins les limites de l'optimisable au niveau de l'algorythmie je pense, mais avec ce genre d'opportunités, ça ouvre de nouvelles portes.
Merci pour ce travail, vraiment passionnant
Citer : Posté le 28/12/2020 23:30 | #
Merci à toi aussi ! Pour Windmill je suis en effet convaincu qu'il y a plein de pistes intéressantes. Je me souviens que j'avais essayé (sans succès) de le compiler avec GCC, je ne sais pas où se situaient les problèmes mais c'est dommage de pas profiter d'un meilleur compilo. Enfin même sous le fx-9860G SDK tu peux utiliser toutes ces merveilles de mémoire donc c'est pas insurmontable