TDM n°7 - Écrire des programmes C avec plusieurs fichiers
Posté le 26/09/2018 16:38
Le Tuto Du Mercredi [TDM] est une idée qui fut proposée par Ne0tux. Un mercredi sur deux, nous postons un tutoriel sur l'Utilisation de la calculatrice, le Transfert, les Graphismes, la Programmation, ou encore la Conception de jeu. Aujourd'hui est le jour de la 7ème édition!
Écrire des add-ins avec plusieurs fichiers sources
Niveau : ★ ★ ☆ ☆ ☆
Ce tutoriel de C est destiné aux débutants du langage, pour qui écrire un add-in avec plusieurs fichiers de code est synonyme de variables globales perdues, pas moyen de communiquer entre fichiers... et aussi à tous ceux qui n'arrivent pas à se convaincre que les fichiers d'en-tête en
.h servent à quelque chose.
Vous verrez que ce n'est pas aussi compliqué que ça en l'air, le problème est que le compilateur ne regarde qu'un seul fichier à la fois, donc il faut lui dire ce qu'il doit s'attendre à voir dans les autres. Et c'est parti !
 Partie I - Comment les programmes C sont compilés
Partie I - Comment les programmes C sont compilés
Contrairement aux programmes Basic, quand vous compilez un add-in qui possède de nombreux fichiers de code (aussi dits « fichiers sources » ou « fichiers
.c »),
tous les fichiers sont compilés indépendamment. Pour chaque fichier source, la compilation crée un fichier
fichier objet (
.o ou
.obj) qui contient du code assembleur. Ce n'est qu'une fois tous les fichiers compilés que l'on commence à les réunir pour former la première version complète de l'add-in (ici
game.elf).
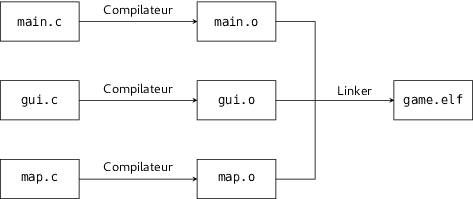
L'intérêt de cette méthode par rapport à compiler tous les fichiers d'un coup, est que si vous avez modifié uniquement
gui.c depuis la dernière compilation, vous n'avez que
gui.c à recompiler, les autres fichiers objets peuvent être réutilisés. Cette distinction qui peut paraître futile pour un petit projet est cruciale pour les gros programmes qui prennent de longues minutes à compiler entièrement.

Cela pose par contre un problème : quand on crée une nouvelle partie,
main.c fait appel à la fonction
map_generate() qui est dans
map.c... mais comme les deux fichiers source sont compilés indépendamment,
comment le compilateur peut-il savoir de quelle fonction je parle et où elle se trouve ?

Eh bien, c'est le programmeur qui donne au compilateur les informations sur la fonction. Il lui indique son nom, ses arguments, le type de sa valeur de retour... c'est-à-dire son
prototype (aussi appelé « signature »). Quant à savoir où elle est, le compilateur s'en moque ! Il indique juste dans le code assembleur « ici il faut appeler
map_generate() » et ensuite c'est le linker, dans la dernière phase de compilation, qui recolle les morceaux et vérifie que toutes les fonctions sont là.
Pour les variables globales, ça se passe exactement pareil : le programmeur indique au compilateur le nom et le type de la variable, ce qui suffit pour compiler ; ensuite le linker recolle les morceaux et vérifie que la variable mentionnée existe bel et bien dans un des fichiers.
Allons donc explorer comment diable on peut indiquer au compilateur qu'il existe dans d'autres fichiers des variables globales et des fonctions que l'on veut utiliser.
Partie II - Déclarations et définitions
Désormais, on veut non seulement pouvoir créer des variables ou des fonctions, mais parfois on veut aussi pouvoir indiquer au compilateur que des variables ou fonctions existent quelque part ailleurs, sans dire où et sans dire ce qu'elles contiennent.
Ces deux actions sont appelées respectivement définition et déclaration.
Les définitions, c'est ce que vous utilisez d'habitude : ça crée un objet qui contient des données ou du code. Tout ce qui porte un nom et existe dans un programme C est défini quelque part.

/* Définition, car crée des données */
int random_number = 42;
/* Définition, car crée du code */
int randomize(int x)
{
return x + 42;
}
Vous n'avez pas le droit de définir plusieurs objets avec le même nom, sinon le compilateur ne pourra pas savoir duquel vous parlez. Le message d'erreur que vous aurez si vous essayez le faire sous le SDK, vous l'avez sans doute déjà croisé (« symbole » est juste un synonyme de « nom » pour le compilateur) :
** L2300 (E) Duplicate symbol "_random_number" in "C:\..."
Par contre vous pouvez déclarer vos objets autant de fois que vous le voulez, quand ils existent autant le faire savoir à tout le monde.

Soit dit en passant, lorsque vous définissez une fonction ou une variable globale, le compilateur va en déduire qu'elle existe (dans le fichier où vous venez de la définir), ce qui la déclare implicitement.
Maintenant, supposons que vous avez défini dans
map.c une fonction
map_generate() et que vous voulez la déclarer dans
main.c pour pouvoir l'y utiliser. Le compilateur a besoin d'un certain nombre d'informations qui sont :
• Le nom de la fonction
• Combien elle a de paramètres et quels sont leurs types
• Quel est le type de la valeur de retour
• (facultatif) Le nom des arguments (totalement ignoré, peut être n'importe quoi)
Essentiellement ces informations forment
le prototype de map_generate(). Pour écrire un prototype, tout ce que vous avez à faire est de copier la première ligne de la fonction (tout jusqu'à l'accolade ouvrante) et ajouter un point-virgule. Par exemple, si la fonction est définie comme ceci :
/* Dans map.c */
int map_generate(double density, int use_noise, int enable_trees)
{
/* ... */
}
Alors vous pouvez la déclarer partout ailleurs, notamment dans un autre fichier, en y ajoutant la ligne suivante :
int map_generate(double density, int use_noise, int enable_trees);
Voilà un exemple d'utilisation tout bête.

/* Dans main.c */
int map_generate(double density, int use_noise, int enable_trees);
void new_game(void)
{
map_generate(0.1, 0, 1);
/* ... */
}
Une part de tarte, n'est-ce-pas !
Si vous êtes malin, vous avez peut-être essayé de mettre un
faux prototype dans votre programme. C'est très dangereux car le compilateur, incapable de vérifier ce que vous racontez puisqu'il n'a pas accès au code de la fonction, va vous croire sur parole et tout peut exploser quand vous appelerez la fonction ! Vous devez toujours faire attention à ce que vos prototypes soient rigoureusement exacts, et les fichiers d'en-tête vous y aideront dans la section suivante.
Mais avant cela, voyons comment on peut faire pour permettre à
main.c d'utiliser une variable globale définie dans
gui.c. C'est presque pareil, sauf que cette fois on utilise le mot clé
extern qui sert à dire que la variable est... à l'extérieur !

/* Dans gui.c */
int number_of_widgets = 42;
/* Dans main.c */
extern int number_of_widgets;
void new_widget(const char *name)
{
number_of_widgets++;
/* ... */
}
Comme vous pouvez le voir, je n'ai pas recopié le
=42 car le fichier
main.c doit juste indiquer au compilateur que la variable existe et se moque de savoir à quelle valeur elle a été initialisée. De plus une déclaration ne doit pas créer de données ;
on ne peut donc initialiser une variable que lors de sa définition.
Vous pouvez aussi mettre
extern dans un prototype de fonction, mais ça ne sert à rien car il y est automatiquement !
S'il n'y a pas une accolade ouvrante avec du code dedans, le compilateur comprend tout de suite qu'il s'agit d'une déclaration.
Si tout s'est bien passé, vous pouvez maintenant partager vos fonctions et variables globales entre plusieurs fichiers. Continuez quand même à lire, la suite est importante !
Partie III - Les fichiers d'en-tête
Maintenant que vous avez mis des prototypes et des déclarations
extern dans tous vos fichiers, vous pouvez enfin utiliser les objets définis dans les autres fichiers.
Mais que se passe-t-il si vous voulez les modifier ?
Mettons que j'ajoute un paramètre à la fonction
map_generate(), il faut que je modifie la définition de la fonction, mais aussi tous les prototypes qui se trouvent partout ailleurs dans le code ! C'est très fastidieux et le risque de se planter ou d'en oublier est énorme !
Eh oui, plus vous dupliquez la même information un grand nombre de fois, plus vous prenez le risque de ne pas réussir à gérer toutes ces copies !
C'est ici que les fichiers
.h interviennent pour nous sauver la vie. Pour rappel, les fichiers d'en-tête sont ceux qu'on inclut en utilisant
#include :
#include <stdio.h>
En fait, cette commande copie littéralement les contenus du fichier
stdio.h (qui se trouve dans un répertoire du SDK) au milieu du fichier source où le
#include a été écrit. Vous voyez où je veux en venir ?
C'est ça, vous pouvez mettre toutes vos déclarations externes et vos prototypes dans un fichier d'en-tête ! Ensuite vous n'avez qu'à inclure cet en-tête chaque fois que vous voulez utiliser une fonction définie dans un autre fichier. Par exemple :
/* Dans map.c */
int map_generate(double density, int use_noise, int enable_trees)
{
/* ... */
}
/* Dans map.h */
int map_generate(double density, int use_noise, int enable_trees);
/* Dans main.c */
#include "map.h"
void new_game(void)
{
map_generate(0.1, 0, 1);
/* ... */
}
Vous noterez que j'ai utilisé des guillemets
"" au lieu de chevrons
<> dans le
#include. C'est la règle quand vous voulez utiliser un fichier d'en-tête qui est à côté de vos fichiers source (dans le même dossier, j'entends).
Il est très important d'
inclure map.h dans map.c parce que même si vous n'avez désormais plus que deux copies de vos prototypes de fonctions, il faut encore qu'ils soient les mêmes ! En incluant
map.h dans
map.c, vous donnez au compilateur la possiblité de vérifier que votre déclaration est conforme à votre définition, et cela renforce grandement la sécurité de votre programme.
Je vous conseille très fortement d'
écrire un fichier d'en-tête par fichier source et ne pas succomber à la tentation de mettre toutes les déclarations dans le même fichier
mon_super_projet.h. Je dois ajouter que jamais, jamais,
jamais vous ne devez mettre de définitions dans un fichier d'en-tête. Le code, il est dans les sources, et nulle part ailleurs.
Résumé
Le compilateur traite tous les fichiers sources indépendamment, il a donc besoin de votre aide lorsque vous utilisez des objets définis dans d'autres fichiers.
Lorsque vous créez un fichier
map.c dont les fonctions vont être utilisées ailleurs, créez immédiatement un fichier
map.h et copiez-y les prototypes de toutes les fonctions qui doivent être « publiques », plus des déclarations externes pour toutes les variables globales « publiques » :
/* Dans map.c */
#include "map.h"
int generated_maps = 0;
int map_generate(double density, int use_noise, int enable_trees)
{
generated_maps++;
/* ... */
}
/* Dans map.h */
extern int generated_maps;
int map_generate(double density, int use_noise, int enable_trees);
Ensuite, tous les fichiers qui veulent utiliser les fonctions de
map.c n'ont qu'à inclure
map.h pour y avoir accès :
/* Dans main.c */
#include "map.h"
void new_game(void)
{
map_generate(0.1, 0, 1);
/* ... */
}
Voilà, vous savez désormais tout sur les interactions entre fichiers dans les programmes à plusieurs fichiers sources ! Si vous avez des questions, lâchez-vous dans les commentaires !
Liens utiles :

Voir le TDM précédent :
TDM n°6 – Principes d'animation.
 Fichier joint
Fichier joint

{kind=link}
Citer : Posté le 26/09/2018 17:33 | #
Merci ces explications détaillées m, elles seront sans aucun doute utiles.
D'ailleurs, nous n'avons pas de section du forum exclusivement réservée au C sur calto ? Il pourrait être intéressant de tout regrouper : le SDK, les headers, différence sh3-sh4, méthode alternatives de compilation (Linux/gint), librairie C...
Citer : Posté le 26/09/2018 17:35 | #
J'ai pensé il n'y a pas longtemps à créer un topic comme ça. Peut-être quand j'aurai plus de temps pour écrire, une fois gint (enfin) sur les rails...
Citer : Posté le 26/09/2018 17:49 | #
À force d'utiliser un makefile (et bosser sur des projets dont la structure est déjà faites), je pense que ça ne me fait pas de mal de revoir les bases (pour quand j'aurai besoin d'y rajouter des trucs
EDIT: Tu viens de m'apprendre la raison pour laquelle on importe le .h dans son propre.c
Citer : Posté le 26/09/2018 18:28 | #
J'ai attentivement lu ton Tuto. Propre, rigoureux (comme je m'y attendais), ton tutoriel explique assez clairement l'intérêt d'utiliser des Header.
Je me permets de poser une question, car je ne code plus en C depuis un bon moment :
Est-ce qu'il n'y a pas des directives de pré-processeur à mettre dans le .h pour éviter qu'il soit mis plusieurs fois dans le fichier final (après toute la compilation) ?
Citer : Posté le 26/09/2018 19:00 | #
Pour répondre à at question Drak, il y'a deux ligne avant le contenu du header : #define MonHeader #include MonHeader et à la fin #EndDefine MonHeader les commandes ne portent pas ces noms là, mais ces trois lignes sont présentes
Citer : Posté le 26/09/2018 19:03 | #
Oui, pour éviter les inclusions en boucle, il faut mettre :
#define _SOME_SYMBOL
struct {
int a, b;
} Yolo;
int function(int a, char* b);
#endif
_SOME_SYMBOL doit être unique pour chaque fichier.
Par convention, _SOME_SYMBOL est souvent le nom du fichier, par exemple _FILE_H pour file.h.
Citer : Posté le 26/09/2018 20:46 | #
Tutoriel adressé aux connaisseurs du language C...
À dans deux semaines
Citer : Posté le 26/09/2018 21:58 | #
J'ai attentivement lu ton Tuto. Propre, rigoureux (comme je m'y attendais), ton tutoriel explique assez clairement l'intérêt d'utiliser des Header.
Merci !
En effet, Dark Storm a bien expliqué comment ça marche. Mais il n'a pas présenté tout l'intérêt. Éviter les inclusions infinies est une chose, mais en pratique le souci est que certaines choses présentes dans les headers sont des définitions.
J'ai donc un peu menti, mais pas trop, car ce ne sont pas les mêmes définitions. Elles ne créent ni données ni code, et ne génèrent pas des octets dans le programme compilé. Ce sont typiquement des définitions de types ou de macros qui servent à gérer le niveau d'abstraction du code.
Un exemple typique est une définition de structure, comme le montre Dark Storm : dans cette situation, on fait quelque chose d'important qui est réserver le nom struct Yolo et qui ne peut donc pas être fait deux fois dans le même fichier source. Il est important que le header ne soit donc pas inclus deux fois. Il y a de nombreux autres exemples.
Toutefois Dark Storm commet deux erreurs que j'ai bien envie de corriger pour l'embêter.
int a, b;
};
Sinon, ce qu'il se passe c'est que le programme est lu comme struct { ... } Yolo, ce que le compilateur comprend comme « un type, struct { ... } » suivi de « un nom de variable, Yolo », et donc la définition crée une variable Yolo donc le type est une certaine structure. Comme cette structure n'a pas de nom puisqu'il n'y a rien entre le struct et l'accolade ouvrante, on la dit anonyme.
Ainsi donc, Dark Storm a mis une définition de variable dans son header ! Impardonnable !
La seconde erreur, c'est d'avoir collé l'étoile à char dans char* b : on n'insistera jamais assez sur le fait que voir char* comme le type de b risque de poser le problème suivant :
/* a est de type char * */
/* mais b est de type char */
En fait la vraie syntaxe pour déclarer deux pointeurs est la suivante :
Je peux vous donner une intuition de pourquoi c'est comme ça. Prenons que vous avez un pointeur vers un int. Parfois vous n'avez pas le droit de modifier l'entier pointé, donc le pointeur est de type const int *. Mais ceci vous autorise à modifier le pointeur (ie. l'adresse) pour allez pointer ailleurs. Si c'est la valeur du pointeur, et pas la donnée pointée, qui est en lecture seule, le const doit être placé après l'étoile, comme ceci : int * const. En multipliant les niveaux de pointeurs et les qualificatifs, on peut avoir un type qui ressemble à ça :
Et là vous comprenez pourquoi on doit mettre une étoile par variable, tout simplement parce qu'on doit spécifier tous les qualifieurs pour chaque variable. L'étoile sert de délimiteur.
(C'était une digression un peu longue, j'espère vous avoir appris quelque chose.
Citer : Posté le 26/09/2018 23:25 | #
Super contenu, bravo ! C'est important de bien s'organiser dès le début et de savoir pourquoi on le fait.
Je fais un peu différemment avec les "extern". Pour les gros projets je créé un "nouveau type d'header" pour n'y mettre que les prototypes/fonctions et consorts qui soient "extern". J'utilise par exemple des .he qui me permettent en un coup d’œil de savoir ce que le reste du programme peut utiliser de mon module (c'est à dire quelles fonctions/variables de mon .c sont accessibles au reste du programme). Les variables/fonctions locales à mon module sont elles mises dans un .h classique.
Je ne sais pas si c'est très clair, mais ça veut dire que tout est "extern" dans mes .he, rien ne l'est dans mes .h, et mon .c ne contient pas "extern" mais include un .he et un .h. Après bien sûr ce n'est qu'une convention perso, chacun prend ses propres habitudes.
- g : variable globale à plusieurs modules (toutes les variables d'un .he sont g)
- m : variable statique au sein d'un module (toutes les variables d'un .h, partagées entre plusieurs fonctions d'un même fichier .c sont m)
- h : variable statique au sein d'une fonction
- o : variable passée en paramètre
Ensuite j'ajoute le type :
- u : unsigned
- s : signed
- q : boolean
- p : pointeur
- a : array
- t : structure
- e : enum
- f : float
- 16, 32, 64
Exemple : gau32_MonTableauGlobalUnsignedTrenteDeuxBits
Si je traite avec une variable qui stocke une valeur liée à une unité alors je l'ajoute toujours en suffixe : _mm, _cpc etc
Pourquoi je parle de ça ? Parce que ce genre de convention peut s'étendre aux noms de fonctions et ça permet de savoir en un coup d'oeil ce que renvoie la fonction par exemple.
La Planète Casio est accueillante : n'hésite pas à t'inscrire pour laisser un message ou partager tes créations !
Citer : Posté le 27/09/2018 07:32 | #
Merci de tes retours, ça fait plaisir !
Je vois ce que tu fais avec tes .he. Tes définitions type structures, elles sont où ? Si je ne me trompe pas, ta méthode consiste à séparer les déclarations internes et externes de tes modules, ce que tout bon projet fait ; mais en général c'est encore plus strict, dans le sens où les en-têtes publics sont dans un dossier public et les en-têtes privés dans un dossier qui n'est accessible que pour les fichiers du module.
J'admets que la notation hongroise me fait un peu mal aux yeux mais elle a ses intérêts aussi. x)
Citer : Posté le 27/09/2018 15:38 | #
Zut, toutes les structures que j'ai créé dans l'exemple de code pour Odyssée sont créé comme celle DarkStorm de >_<
EDIT: A ma décharge, j'ai pris exemple sur un morceau de code d'Arena
Citer : Posté le 27/09/2018 15:46 | #
Toutefois Dark Storm commet deux erreurs que j'ai bien envie de corriger pour l'embêter.
int a, b;
};
Ouaip, c'est parce que j'ai l'habitude de toujours faire un typedef sur mes structures, du coup ça donne en pratique
…
} object_t;
Je reconnais que c'est bancal et que ça pose problème si par exemple si on veut ajouter un pointeur sur la structure dans la structure (cas des listes chainées entre autres).
Pour le char* a, chacun a sa sauce. Tant que tu fais pas la boulette
Mais je préfère largement « une variable de type pointeur sur char » à « une variable de type char, mais en pointeur » (je sais pas si je suis clair
Citer : Posté le 27/09/2018 16:00 | #
Oui, je me doute bien que c'était ça ! D'ailleurs si on regarde comment le compilateur comprend ton typedef :
Tout s'explique !
En plus tu peux faire ça :
{
int data;
struct node *next;
} node_t;
Citer : Posté le 05/10/2018 17:36 | #
Ce tutoriel ne figure pas encore parmi la catégorie "tutoriels du mercredi" ! N'oubliez pas !
Citer : Posté le 05/10/2018 19:05 | #
En effet, je l'ai ajouté !