Windmill : moteur graphique 3D - PARTAGE DES SOURCES
Posté le 30/09/2016 00:44
Windmill
Bonjour, bonsoir !
Windmill est un moteur graphique 3D pour calculatrices CASIO monochromes.
Ce topic est le journal de bord du projet, il décrit l'avancée étape par étape, jour par jour, depuis la création du projet à aujourd'hui.
Début du projet : juillet 2016
Dernière mise à jour : mars 2019
Dernière démo : jour 22
Un petit brief d'abord :
Windmill est un moteur graphique 3D, il est capable d'afficher des objets définis en trois dimensions.
Le principe de base du moteur graphique est de décomposer en triangles un modèle 3D puis d'appliquer des textures sur ces triangles en gérant l'occlusion.
Sur calculatrice, il n'existe aucune libairie dédiée à le 3D, donc Windmill a été écrit à partir d'une feuille blanche, tout à été réalisé de A à Z.
Jour 1
Cliquez pour recouvrir
Dans la vidéo, j'ai optimisé le moteur graphique pour les murs verticaux. c'est à dire qu'il ne dessine plus des triangles mais des trapèzes, j'ai commencé l'optimisation pour les murs horizontaux récemment.
La bonne nouvelle c'est qu'il reste une grosse marge de progression pour optimiser ces cas particuliers : éviter les flottants, gérer un peu mieux le clipping, le back face culling et éviter un calcul redondant dans la boucle principale.
Jour 2
Cliquez pour recouvrir
Principalement un gros travail sur l'optimisation des murs : la plupart des calculs flottants sont désormais avec des entiers, le clipping est géré (on affiche pas les pixels en dehors de l'écran), des calculs sont simplifiés, et même pour gagner encore quelques fps les textures doivent être tournées de 90°.
Désormais les murs horizontaux peuvent être affichés, et même le plafond noir (avant c'était de la triche juste pour la vidéo...), des textures peuvent être appliquées sur le sol, et on peux construire des objets telle que la caisse ici présente.
Les textures peuvent être changées pendant le jeu, ainsi cela permettra d'afficher des textures animées comme de l'eau par exemple !
Il y a trois types d'objets affichable :
- les murs. De face ou de coté.
- les étages. Il s'agit d'objets plats, par exemple le sol, le paillasson, le haut de la caisse.
- le plafond. C'est un étage optimisé pour le noir.
Tous les objets sont paramètrables, de la taille, la hauteur, la texture que l'on veut.
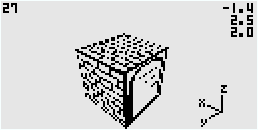
Jour 3
Cliquez pour recouvrir
Simplement un aperçu de la vue de coté, en fil de fer cette fois parce que je n'ai pas terminé l'algo pour afficher les textures sur les murs.
J'ai déjà la structure de l'algo pour appliquer mes textures, il me reste plus qu'a l'implémenter. Il ressemble à celui que j'ai déjà mais avec une variante. Cependant je vais le reprendre de zéro pour être certain d'optimiser au mieux.
Parce que avec cette vue il y a beaucoup de chose qui changent :
- les textures appliquées sur le sol, au plafond ne sont plus des sprites classiques, elles sont maintenant déformées ce qui implique d'utiliser l'algo "lourd" et pas un simple affichage de sprite zoomé (cf la lib ML_zoom)
- les murs orientés vers le "sud" ne sont plus visible car toujours vu par "derrière" donc plus besoin d'être géré. Ça c'est une bonne nouvelle, mais je ne pense pas que ça puisse compenser le point du dessus.
Donc en conclusion, j'ai peur quand aux performances de l'ensemble fini. Il va arriver un moment où ça risque de coincer.
Jour 4
Cliquez pour recouvrir
GROSSE GROSSE nouveauté ! Comme promis le moteur gère la vue de coté !!
Pour cela j'ai totalement repris mon algo de base pour appliquer les textures sur des triangles avec un bon passage à la moulinette de l'optimisation, et j'ai ainsi multiplié par 11 les performances ! C'est énorme !
La prochaine étape est d'implémenter le Z-buffer pour ne pas voir à travers les murs, et encore un tas d'optimisations...
Et maintenant il n'y a pas de cas particuliers dans l'algo, c'est à dire que je peux tourner la caméra dans tous les sens, afficher des formes dans n'importe quelle position (mais ça ce sera pour une prochaine vidéo )
Jour 5
Cliquez pour recouvrir
Et voilà encore du nouveau ! (Oui ça avance vite )
Maintenant j'ai rajouté le z_buffer qui permet de ne pas afficher les murs sensé ne pas être visible.
Et j'ai rajouté un degré de liberté pour la caméra, ce qui permet de tourner sur soi-même.
Il reste encore un tas de choses à améliorer (meilleur rendu des textures, déplacement de la caméra selon différents repères) et d'optimisations (accès à la vram plus intelligent pour éviter de dessiner du banc si c'était déjà blanc, passage des calculs pour les rotations, les projections et les produits vectoriels en nombres entiers).
Je vais mixer un peu le rendu avec le mode fil de fer pour les murs vu par derrière (qui sont transparents actuellement). J'ai déjà fait quelques test et on se rend mieux compte des volumes !
Jour 6
Cliquez pour recouvrir
J'ai amélioré la qualité du rendu général en jouant sur les décalages de bits de façon plus astucieuse, en simplifiant des opérations et en arrondissant les nombres flottants. Résultat moins de perte à cause d'arrondi et de troncature, les textures sont moins déformées et plus précises. J'ai encore optimisé mon algorithme pour appliquer les textures, j'étais passé à côté de quelque chose d'énorme, résultat j'ai pu simplifier encore mes calculs pour gagner 35% de performances. Je suis passé de 10 décalages de bit, 17 mults, 9 additions à 7 décalages, 12 mults et 10 additions.
J'ai apporté quelques modifications au z-buffer (qui permet de ne pas afficher les objets caché par d'autres), l'initialisation est plus rapide et il est plus stable car il ne risque pas de d'overflow. Et je ne dessine plus de pixel blanc si c'est la première fois que je dessine sur un pixel puisqu'il était forcement blanc avant.
J'ai rajouté la gestion des viewport, c'est à dire que le rendu peu être dans une fenêtre définie par le programmeur et plus forcement sur l'écran entier. C'est utile si on utilise un ATH qui prend une partie de l'écran ou dans un menu pour afficher un objet 3D dans un coin facilement. Je n'ai pas testé, mais il est théoriquement possible d'afficher deux rendus différents en même temps, un écran splitté pour le multijoueur par exemple
Jour 7
Cliquez pour recouvrir
Il n'y a pas grand chose de nouveau visuellement donc je sors pas de vidéo, mais maintenant que j'ai fini d'opimisé le rendu des textures, j'ai optimisé la transformation des points dans l'espace 3D. J'ai gagné 71% de rapidité depuis le jour 6 ! Entre autres, j'ai précalculé les cos et sin, les coefficients de la matrice de rotation, le tout avec des nombre entiers.
Ce qui me prend du temps en ce moment c'est la structure de mes données, comment faire quelque chose d'efficace et qui permette d'écrire les modèle 3D rapidement à la main. Donc je gère des mini structures toutes faites, des triangles, des rectangles, et peut être d'autres plus tard comme des cylindres.
De plus, j'ai ajouté une fonctionalité qui permet d'appliquer une texture des deux cotés d'un triangles. Mais un problème est apparu, quand deux textures sont trop prochent l'une de l'autre, elle on tendance à se chevaucher, c'est à dire que la texture qui est derrière est affichée par dessus celle de devant...Ici on voit la texture blanche qui passe par dessus le mur de brique (frame 2 à 7)
Ça fait une journée que je cherche le problème. Il vient evidemment du z-buffer, mais la raison du problème est assez floue
Jour 8
Cliquez pour recouvrir
J'ai réussi à repérer l'origine de mon problème après plusieurs longues séances de documentation et de débeugage.
L'utilisation des matrices de projection perspective m'a permis de remapper la coordonnée z de mes points dans l'espace caméra, c'est à dire que maintenant leur coordonnée z à une valeur logique : elle est définie à 0 quand le point est sur le near clipping plane et à 1 sur le far clipping plane. Deux plans que je définie moi même.
Ceci m'a permis de mettre au jour une relation très vicieuse entre mes triangles que je n'avais pas remarqué jusqu'à présent. Je m'explique : dans ma phase de simplification, j'ai remarqué qu'une division était inutile puisque qu'elle se simplifiait dans une multiplication un peu plus loin. Dans le même genre que (A / B) x (C x B) = A x C
Cela n'a pas posé de problème de simplifier, j'ai obtenu exactement le même rendu.
Cependant, et c'est là que c'est vicieux, c'est que, plus tard, en rajoutant mon z-buffer (qui permet de connaître la distance entre mon point et la caméra afin d'afficher uniquement le plus proche), j'ai fabriqué une relation cachée entre mes triangles. En effet ils ne sont plus dessinés independamment puisqu'ils partagent le même z-buffer.
Et comme j'ai utilisé uniquement A et pas A / B et que B varie d'un triangle à l'autre, les données que je rentrais dans mon z-buffer étaient faussent.
Mais comme B varie peu, le problème ne s'est pas montré au premier abort, mais il était bien là !
Maintenant que je comprends l'origine du problème, je vais pouvoir le résoudre. En tout cas, c'était bien tordu et ça m'a bien pris la tête.
Désolé pour ce passage assez technique, mais expliquer l'origine du problème ne peut pas se faire sans
Jour 9
Cliquez pour recouvrir
Et voilà problème réglé ! Enfin, ça m'a pris une journée complète. (j'ai bien perdu 1h sur un copier coller raté et 3h parce que j'avais pas mon café...)
Maintenant le z-buffer est ultra propre ! je maitrise vraiment tout se qui passe. Un bon point pour la stabilité et éviter l'apparition d'artéfactes visuels
Jour 10
Cliquez pour recouvrir
J'ai commencé à modéliser des vrais objets pour voir ce que mon moteur a dans le ventre, et le résultat est renversant !
En définissant toutes les faces du moulin à vent, j'ai pu créer avec une relative simplicité un résultat plus que correct.
D'un point de vue technique, j'ai de nouveau optimisé depuis le jour précédent, en effet j'avais tout "désoptimisé" pour résoudre mon problème. Les fps en temps réel sont affichés dans le coin de l'écran, on voit que pour un modèle aussi riche (30 triangles) la vitesse du rendu est plus que convenable ce qui démontre que ce projet est viable. De plus il me reste quelques points à optimiser, sur le calcul des coordonnées de textures je peux grater pas mal, j'ai deux divisions que je peux transformer en une seule, et quelques autres idées. Donc j'ai encore de la marge, l'objectif étant qu'a terme le rendu soit le plus véloce possible
Sinon on peut remarquer que j'applique des textures sur des triangles dans des positions quelconques (le toit et les pales) et que j'ai ajouté l'option pour afficher une texture différentes de chaque côté d'un triangle (le toit vu par en dessous est noir) et j'ai rajouté un paramètre pour une bonne utilisation des textures sur les triangles (en effet le sprite est un carré à la base).
La prochaine étape est une réorganisation du code, j'ai deux fichiers que je vais réunir en un seul et je vais revoir comment le moteur recoit les objets à afficher. Dans la prochaine vidéo, les pales du moulin tourneront (enfin je l'espère bien )
Jour 11
Cliquer pour enrouler
Jour 11
Maintenant le moteur peut afficher plusieurs objets différents et les objets dynamiques ! J'ai revu totalement la façon de fournir les objets à afficher au moteur. Maintenant on peut afficher plusieurs objets simultanément, et on peut définir des mouvements pour les objets.
Jour 12
Cliquer pour enrouler
Jour 12
Après une grande pause, le projet reprend, en fonction de ma disponibilté, plus faible qu'avant, mais toujours présente
Comme je l'avais annoncé, la reprise de mes travaux portent sur l'optimisation, la résolution de bugs, et des changements internes pour les nouveautés à venir.
- nettoyage du fov, la valeur qui correspond à l'angle de vision, c'était un peu au pif avant.
- mise en const des variables de la map : les textures, les objets, les triangles et les rectangles.
- j'ai clarifié la précision des fixed (des nombres entiers utilisés comme des nombres à virgules) pour éviter les débordements, c'est surtout problématique pour les objets lointains, ou très proches car des variables s'approchent des limites d'un int.
Maintenant je suis certain qu'afficher un objet à la taille minimale (de taille 1) ne pose aucuns problèmes.
un cube de côté 1 :
un cube de coté 10, avec à sa droite le cube de coté 1.
(On voit le sol à partir de cette échelle, la distance entre les points est de 10)
L'histoire d'échelle est d'ailleurs très subjective, à combien correspond une taille de 10 si on veut la comparer au monde réel ? J'ai fait la proposition suivante : 1 = 10cm
- j'ai ajouté un repère 3D dans un coin de l'écran, c'est utile pour le debug.
- j'ai sorti la camera de la scène, c'est à dire que j'ai crée une classe juste pour la caméra.
- correction d'un problème dans le z-buffer (un tableau de la taille de l'écran enregistrant la distance des pixels par rapport à l'écran), j'avais un overflow, maintenant c'est tout propre !
- nettoyage divers dans le code
Jour 13
Cliquer pour enrouler
Jour 13
J'avance lentement, j'ai assez peu de disponibilité depuis 2 semaines...
MAIS ! Windmill avec encore et toujours
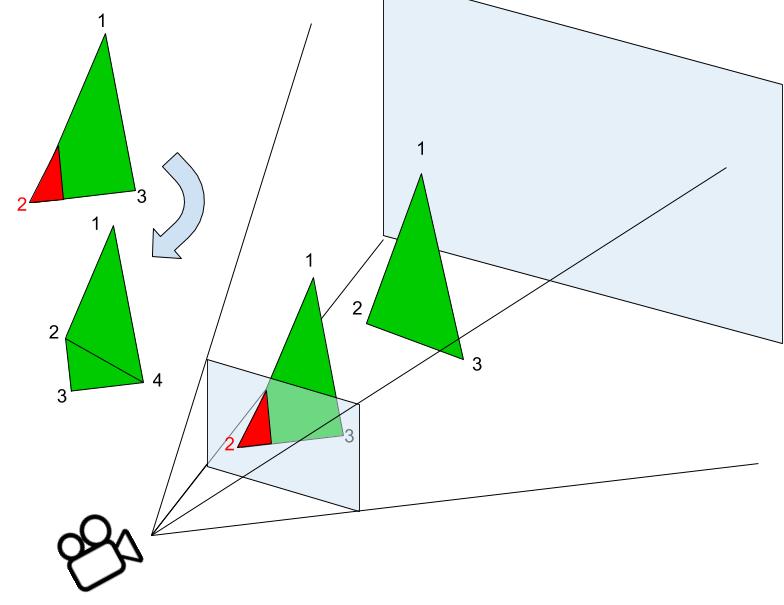
J'ai ajouté une fonctionnalité qui manquait depuis un long moment mais qui est pourtant essentielle : l'affichage des triangles devant le plan de clipping...
Explication :
Je parlais plus haut des plans de clipping, le proche et le lointain. Ces deux plans parralèles forment une pyramide avec à son sommet la caméra. Tout ce qui est entre ces plans est affiché. Le problème c'est si un point du triangle est avant le plan proche, jusqu'à présent si un des points avaient une coordonnée en z négative je n'affichais tout simplement pas le triangle.
Pour résoudre celà je tronque ou divise, en fonction des cas (1 ou 2 points devant le plan)
Desormais il n'y a presque plus de cas où des triangles disparaissent
Jour 14
Cliquer pour enrouler
Jour 14
Le problème de clipping que j'exposais en jour 13 est résolu !
Voici un petit rendu que comment c'était avant et comment c'est maintenant, le triangle (qui est la brique essentielle de tout le reste) est maintenant affichable avec beaucoup plus d'angle. Même quand on est presque dans le mur, il s'affiche correctement.
La texture se déforme légèrement quand on est vraiment proche, c'est dû aux erreurs d'arrondi.
Bonne vidéo
Jour 15
Cliquer pour enrouler
Jour 15
Une grosse surprise se prépare. Encore quelques soucis en train d'être corrigés et vous allez en prendre plein les yeux promis
En attendant cette semaine j'ai corrigé quelques bêtes erreurs comme un 1204 au lieu d'un 1024.
Changé un tas de chose en interne pour homogénéiser mon code
Les ajouts depuis le jour 13 :
Ajouté une ligne d'horizon (c'est tout bête mais ça rend bien mieux)
Changé les coordonnées des textures, maintenant on définit la taille en pixel en la texture, et la taille dans le monde.
Par exemple un texture de 32x32 peut correspondre à un carré de taille 20x20 (soit 2m carré), ou plus, ou moins c'est au choix.
- En affichant cette texture sur un rectangle de taille 40x40, la texture va automatiquement boucler.
- En renseignant 0x0 en taille réelle, la texture va s'étirer sur son support au lieu de boucler.
C'est très pratique pour répéter des motifs sans avoir à créer un autre rectangle, ou alors pour appliquer une texture sur n'importe quelle surface.
Actuellement j'ai un problème de serpent qui se mort la queue, clipping() doit être executé avant afficher() et afficher() doit être executé avant clipping() sinon j'ai des triangles qui s'effacent à certains moment. Je suis en train de corriger ça, mais c'est un peu casse tête
j'ai une grosse piste d'optimisation, si ça fonctionne j'estime à +30% de fps !
Jour 16
Cliquer pour enrouler
Jour 16
Désolé si tu es venu sur ce topic en pensant que j'ai enfin lancé LA démo ultime que j'ai vendu au jour 15.
Aujourd'hui c'est résolution de bugs.
J'ai résolu le problème du serpent qui se mort la queue en créant une fonction dédié plus rapide. Le problème était de savoir quelle face du triangle afficher, pour rentrer les dimensions de la textures dans les points.
Le problème que j'ai maintenant est une erreur d'overflow, lorsque la surface du triangle à afficher est trop importante, les nombres prennent des valeurs qui dépassent les limites d'un int (+- 2 milliards) et provoquent des bugs terribles sur l'affichage des textures.
J'ai bien ciblé le problème, je sais exactement quand, comment et pourquoi il se produit, je ne sais juste pas comment le résoudre simplement.
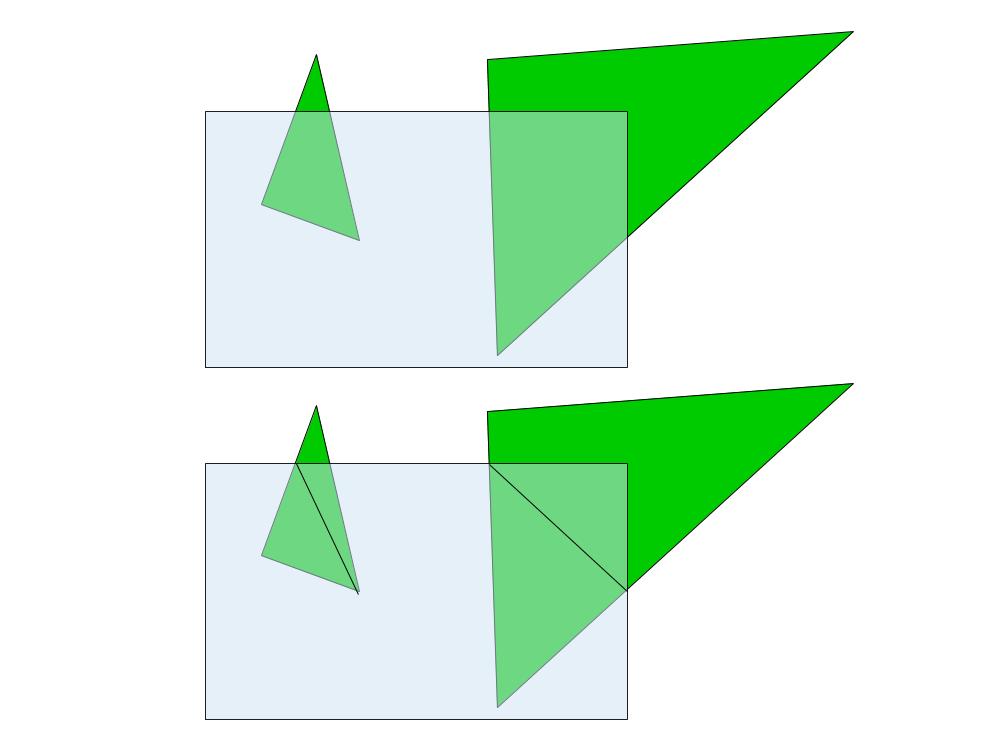
Après 3 soirées gachées à essayer de bricoler un truc, j'ai décidé de faire une autre fonction de clipping.
Cette fois l'objectif n'est pas découpe en plusieurs triangles ceux qui passent derrière la caméra (comme au jour14), mais découper pour n'avoir que les pixel qui sont à l'écran.
Le petit triangle s'affiche sans procblème, le grand à une aire qui overflow et bug visuellement
Jour 17
Cliquer pour enrouler
Jour 17
Le problème de clipping est résolu !
Pour récapituler, j'ai intégré du clipping sur l'axe devant-derrière pour couper les triangles passant derrière la caméra. Puis j'ai créé une nouvelle fonction pour découper les triangles sur l'axe haut-bas/droite-gauche, c'est à dire les bord de l'écran pour régler des problèmes d'overflow (cf jour 16). Le résultat est que le moteur est capable d'afficher des triangles dans n'importe quelle position, même la plus tordue sans bug, ou déformation du triangle.
A cette occasion j'ai revu toute la structure interne pour gérer l'affichage des objets. Je commence avec 1 triangle, et le clipping peux me renvoyer 1 à 10 triangles. Au lieu de gérer chaque point individuellement et avec des conditions à n'en plus finir, j'ai tout inséré dans un tableau que j'envoie à mes fonctions, et tout roule tout seul. c'est beaucoup plus léger et propre.
J'ai rajouté une synchronisation de la caméra avec le rendu. Le déplacement de la caméra (gestion du clavier) est appelé par un timer à interval régulier, ce qui peut tomber pendant le rendu d'une frame. Du coup je commence à dessiner un objet en regardant sous un angle X, la caméra se mets à jour et je termine de dessiner l'objet sous un angle Y. Ça provoquait des secousses et bugs visuels.
Résolution d'un bug sur le z-buffer.
Correction des quelques soucis avec le rendu du sol.
Un peu d'optimisation sur quelques variables.
Le moteur est super stable et il n'y a plus d'artéfactes visuels majeurs !!
C'est un vrai plaisir à regarder Pour ça rien de mieux qu'une vidéo !
Je teste ici sur émulateur et sur la machine, c'est quand même suffisament fluide, environ 10 fps, sachant que cette valeur est doublée avec de l'overcloacking
Jour 18
Cliquer pour enrouler
Jour 18
Windmill avance toujours, bien que la dernière vidéo soit impressionnante, il reste beaucoup de choses à faire.
Voici les nouveautés de la semaine :
- Réorganisation du code. J'ai ajouté une class Player et une class Engine avec un tas de petites modifications. Maintenant on peut créer son propre moteur physique et de gestion du jeu totalement indépendant du rendu 3D.
On peut même créer des moteurs physiques différents. Je suis en train d'en coder 2 :
>> Moteur de déplacement d'un personnage. En vue classique style FPS, on peut courrir, sauter, regarder dans toutes les direction (@Lephé : tout est fluide), interagir avec les objets (porte, trappe, ...)
>> Moteur de création de map. En vue de haut uniquement, on peut selectionner un objet, le déplacer, le tourner et observer ses coordonnées en temps réel. Une fois au bon endroit, il suffit d'écrire les coordonnées en dur dans le code. Très pratique pour créer une map.
- Ajout des billboard. Ce sont des sprites qui font toujours face au joueur. Il tournent sur l'axe vertical pour toujours faire face à la caméra. J'ai crée des arbres avec et des personnages avec.
- Ajout des masques alpha. Chaque texture doit avoir un sprite, et peut avoir un masque. La texture est dessinée que si le pixel du masque est noir.
- Ajout des sphere englobantes. Au chargement d'une nouvelle map, Windmill calcule automatiquement une sphere englobante pour chaque objet. Ceci permet de faire un test rapide. Si la sphere n'est pas à l'écran, aucune utilisté de vérifier si tous les triangles à l'intérieur sont à l'écran. Pour l'instant j'ai fais l'algo pour créer le spheres, il me reste l'algo pour savoir si elles sont à l'écran. J'ai mesuré les fps avant pour faire la comparaison.
- Ajout d'un tas de petites modifications.
- J'ai commencé à rédiger un manuel complet pour utiliser Windmill
Donc voilà, pas mal de nouveautés, c'est à chaque fois de plus en plus impressionnant
Jour 19
Le jour 19 arrive rapidement après le jour 18 car il y a une bonne nouveauté qui fera sans aucun doute plaisir à entendre !
J'ai terminé l'algo des sphères englobantes pour ne pas "chercher" à afficher les objets qui ne sont pas à l'écran.
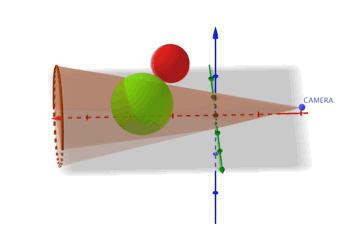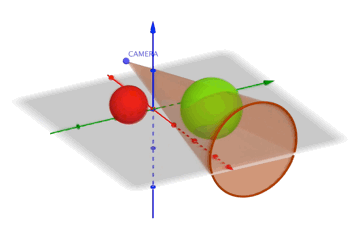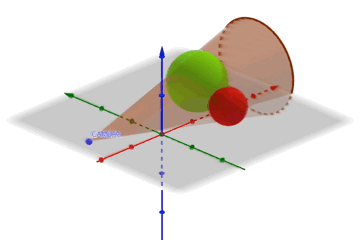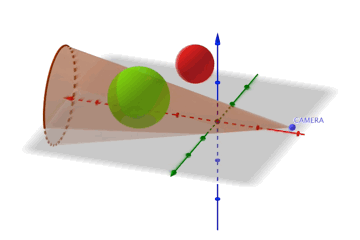
Une petite explication plus détaillée
Lors du chargement de la map, un premier algorithme génère pour chaque objet une sphère qui englobe tous ses points. Lors du rendu, un second algorithme test pour chaque objet, si sa sphère est intersecte ou est incluse dans le champ de vision de la caméra. Si c'est le cas, on dessine l'objet, dans le cas contraire l'objet est ignoré.
Soit N le nombre de point d'un objet composant un objet, au lieu de calculer à chaque fois N points, on calcule au pire N+1 (N+centre de la sphère) ou au mieux 1 point. C'est très rentable !
Voici une animation représentant 2 sphères. La rouge est hors du champs de vision, la verte est dans le champs de vision.
Le gain en fps est d'autant plus important que le nombre d'objet hors du champs de vision est important. Donc impossible d'exprimer un gain fixe en fps.
Voici un comparatif :
Cas n°1, la map est peu chargée (celle en exterieur)
avant après
Tous les objets hors du champs de vision : 67 85
La moitié des objets dans le champs : 28 32
Cas n°1, la map est fort chargée (j'ai ajouté 15 moulins sur la map)
avant après
Tous les objets hors du champs de vision : 35 83
La moitié des objets dans le champs : 22 32
On remarque qu'avec cette méthode, les objets hors ne baisse pas (ou très peu) les performances.
En plus de cela, ça m'ouvre des opportunités pour de nouvelles foncionnalités
Jour 20
Une petite nouveauté dont je parlais précédemment : le trie des objets en fonction de la distance à la caméra.
Windmill trie en continue les objets pour afficher ceux qui sont les plus près en premier. En vérité Il trie les sphères englobantes.
Par exemple, j'ai placé 7 "murs" les uns derrière les autres.
Quand les objets sont dessinés du plus loin au plus proche : 10 fps
Quand les objets sont dessinés du plus proche au plus loin : 17 fps
Le trie permet garantir le second cas.
Cette fonctionnalité permet d'ajouter encore des objets sans perte majeure de performances
Jour 21
Bon... Ça fait un bon moment que je vous promets une démo pour le fameux et si attendu "jour 21".
Depuis le jour 20 il y a eu de gros changements, en interne comme en externe, visibles ou non visibles.
Je vais vous présenter l'ensemble de nouveautés en attendant la prochaine démo, qui sera pour le jour 22 du coup.
D'abord... Windmill gère les collisions avec le décors !!!
J'ai intégré un algorithme qui génèrement automatiquement au chargement de la carte des boites de collision à partir du modèle 3D. Donc le personnage bute sur les murs d'une maison, mais peut aussi monter sur une caisse. En effet le moteur de collision fonctionne dans les 3 dimensions.
Ensuite... Windmill intègre un algorithme de post traitement de l'image.
Cet algorithme détecte les contours des objets et les dessine en noir. Ceci permet de mieux apprecier les volumes.
Et surtout, il simplifie la création des modèle 3D (je développerai pourquoi plus tard)
Après... Windmill gère les "décorations".
Il s'agit d'objets que l'on peut poser en superposition sur les murs pour ajouter du détail. L'objectif est encore une fois de simplifier (énormément) la création des modèles 3D. Avant, pour ajouter une porte sur un mur, il fallait découper le mur en plusieurs parties pour éviter les bugs d'affichage. Maintenant, il suffit de placer la porte où on veut par dessus un unique mur. Il reste néanmoins quelques petits bugs d'affichage avec cette méthode, mais elle fonctionne 90% du temps.
Enfin... beaucoup de remaniement en interne
J'ai nettoyé l'ensemble du code. Il y a maintenant une gestion par scene facilitant la gestion des différentes parties du jeu : l'écran titre est une scene, la map est une autre scene, le menu de sauvegarde sera une scene...
Modification de l'étalement des textures sur les objets
Ajout d'un moteur de création rapide de map, il permet de sélectionner, déplacer et tourner un objet en affichant en direct ces coordonnées. C'est une scene de debug extremment utile pour agencer les objets sur la carte.
Réunion de toutes les variables à sauvegarder dans une même classe, en prévision de la sauvegarde/chargement de partie.
Diverses améliorations
Le jeu tourne forcement moins vite avec l'ajout de ces nouvelles fonctionnalités. Le moteur physique n'influe presque pas, par contre le post traitement diminue entre 5 et 15% les fps. Je dispose cependant toujours de pistes d'optimisation, mais elle ne seront pas fabuleuses non plus. Quoi qu'il en soit, Windmill est toujours parfaitement jouable !
Jour 22 : 22 mars 2019
Bon, je suis malheureux de plus trop bosser dessus, du coup je vous donne le dernier g1a que j'ai compilé !!!
Je souhaitais faire un effet encore plus Wahou en ajoutant encore quelques trucs mais je me rends compte qu'il ne sortira jamais sinon.
Et vu le nombre de fois que je vois passer le Windmill je ressens l'impatience des gens
Je vous laisse vous balader dans ce village virtuel
La grosse nouveauté est, je le rappelle, le moteur physique, essayez de monter sur les bottes de foin ou de sauter par dessus les barrières
Jour 23 : 01 mai 2019
Je commence à en voir de le bout de cette documentation !
J'y ai consacré de nombreuses heures. C'est pour moi un point essentiel pour comprendre comment créer un environnement en 3D à travers Windmill.
De plus, elle n'arrive que tardivement car il fallait s'assurer que les bases du moteurs soit stables et qu'il n'y ait pas de revirement majeur dans la façon de créer une carte. Sinon cela aurait été du travail pour presque rien.
Maintenant c'est assez modulaire pour que l'ajout de nouvelles fonctionnalités se fasse de façon transparente pour vous, au même titre qu'une mise à jour de logiciel.
Vous trouverez ci-joint la documentation dans sa version 3.0. A priori elle devrait suffire pour couvrir les bases de la création d'une carte sous Windmill.
Je posterai les sources par la suite, je vais prendre un peu de temps pour clarifier quelques point au niveau du code
Jour 24 : 02 septembre 2021
Après une longue période sans nouvelles officielles je vous annonce officiellement que Windmill tourne avec les derniers (et même un peu plus) standards de compilation : Gint & C++
Il m'aura fallu bien plus de temps que je ne l'imaginais pour installer Gint, comprendre son fonctionnement, comprendre le fonctionnement du terminal, adapter le code du jeu... J'avais un peu avancé sur l'adaptation en y allant cran par cran jusqu'à ce le C++ soit un obstacle pour continuer.
Lephénixnoir ce sera bien démené mais nous y sommes arrivé !
Que du texte, pas grand chose à montrer, hormis un rendu pas très joli.
Il faut que je refasse une passe sur le code pour voir ce qui cloche car les textures ne sont pas sur bien rendu, il doit y avoir quelques erreur de calculs de ci de là.
Et il faut aussi que je regarde pourquoi le jeu crach dès que je regarde trop à droite ou à gauche.
J'ai a nouveau la main pour avancer comme il se doit. Des nouvelles prochainement sans doute !
Jour 25 : 12 novembre 2021
Bonjour à tous !
La dernière vidéo de Sebastian Lague (I Tried Creating a Game Using Real-world Geographic Data) détaille à 24min moment comment générer des ombres pour un rendu 3D. Je pensais que c'était hyper complexe comme sujet mais en fait c'est assez simple. En fouillant un peu je suis tombé sur une méthode encore plus simple, qui parait trivial une fois dites mais il fallait penser Planar Shadow. J'ai bien l'intention d'implémenter ça
J'ai encore du mal avec le passage sous Gint, avec des bugs dont j'ai du mal à me dépatouiller.
Autre chose, je vais désormais avoir une 90E, donc un truc bien plus récent que ma calto SH3, et avec la couleur, je pourrai faire des tests sur le portage pour cette plateforme ! On verra ce que donnent les performances.
J'ai encore un autre projet, c'est de créer un importeur de fichier obj. L'obj est un format 3D simple à générer, et aussi simple à parser. Le but est de simplifier la création des modèles 3D en passant par un logiciel 3D plutôt que créer à la fin la liste des triangle, c'est fastidieux. Ici une maison crée sous Fusion 360 en 1 minute. On voit le maillage avec les 16 triangles.
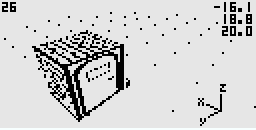
Jour 26 : 5 janvier 2022
Bonne année à tous, me revoici avec des nouveautés concernant Windmill.
Les nouvelles fonctions que je vous décrivais dans le "jour 25" et surtout les ombres et le passage en obj nécessitent une refonte du système de clipping décrit dans le jour 14.
Ce qui change ? Je passe d'un clipping 2D à un clipping 3D.
En somme, je tronque les triangles du modèle en étant encore dans l'espace 3D et plus dans l'espace 2D, c'est à dire un cran avant.
C'était un peu de boulot mais ça me permet désormais d'avancer.
Je vous présente une petite vidéo qui illustre le clipping d'un triangle par rapport au frustrum (la pyramide de vision de la caméra). Le chiffre indique le nombre de trinagle résultant du découpage
Jour 27 : 26 octobre 2022
Bonjour à tous,
La programmation sur calculatrice est chronophage et je n'ai plus de temps perso à y accorder.
J'ai des envies pour ce projet, et pas des petites : passer à la couleur, mettre en place les ombres, terminer l'import au format stl. Ça me motive à fond. Dans le même temps côté boulot, j'utilise le C# et dès que je replonge dans le C ou C++ c'est un retour en arrière qui me frustre. Je passe plus de temps à débugger Windmill qu'à faire ce qui me plait. Je n'avance pas.
J'ai finalement vendu ma 90E avant qu'elle ne prenne la poussière, que les touches se mettent à gripper et que les araignées y fassent leur nid.
Pour être honnête, je ne pense pas remettre un pied dans le projet.
Windmill a souvent été pris en exemple pour l'exploit technique et son potentiel, et je n'en suis pas peu fière. Je ne pense pas qu'une autre personne de la communauté (fr ou non) soit allé aussi loin dans la création d'un vrai moteur 3D pour calculatrice.
C'est pourquoi ce projet doit continuer à vivre et ne doit pas tomber dans l'oubli.
Ainsi je partage à la communauté les sources du projet aujourd'hui.
C'est brut, tout n'est pas commenté, si vous souhaitez reprendre le projet, bon courage, mais merci si vous vous lancez !
Oui bien sûr, le DMA (Direct Memory Access [Controller]) c'est un composant électronique qui est capable de transférer des données à l'intérieur de la calculatrice pendant que le processeur fait autre chose.
Ici, ce qui nous intéresse c'est d'envoyer les données graphiques de la mémoire à l'écran, et sur Graph 90 c'est le facteur de performance numéro 1 quand on fait quoi que ce soit en temps réel.
En effet, si le processeur doit faire le transfert de la mémoire à l'écran lui-même, le temps de transfert est si long qu'on ne peut même pas tenir 20 FPS, et je ne parle même pas de dessiner les frames.
Par contre, si le DMA fait le transfert, non seulement c'est plus rapide mais en plus le processeur peut dessiner le frame suivant pendant ce temps. Cela permet d'atteindre des fréquences d'affichage raisonnables.
Il faut le paramétrer, c'est un poil technique mais c'est faisable. @Nemhardy s'en est déjà servi, il me semble.
Dans tous les cas, utiliser ou non le DMA ne change pas le reste de ton programme, donc tu peux toujours programmer ton rendu et te soucier ensuite de comment tu l'affiches. Utiliser Bdisp_PutDisp_DD() est suffisant pour un début.
Es-tu bien familier avec le C/C++ ou autre langage que tu comptes utiliser ?
Pas d'inquiétude, tu peux y aller sans te poser trop de questions tant que tu fais attention à bien comprendre quand tu rencontres des erreurs !
Leno a écrit : Et je maitrise déjà bien le basique qui en est assez proche si je ne me trompe pas ?
Il n'y a pas beaucoup de points communs en fait, à part le fait qu'il y a des variables, des conditions et des boucles ce n'est pas le même genre de langages !
Merci pour avoir partager tes impressions ici Leno. En effet je me suis grandement basé sur le site ScratchAPixel. Mais d'autres sites vulgarisent davantage.
Sinon, retour aux choses sérieuses !
J'ai besoin d'optimiser à fond quelques lignes de code :
bool flag = false;
for (int i = 0; i<z_buffer_size; i++)
{
current = z_buffer[i];
if (current == MAX_DEPTH_Z_BUFFER)
{
if (flag == true)
{
mask = 128 >> ((i-1) & 7);
vram[(i - 1 - z_buffer_offset)>>3] |= mask;
flag = false;
}
} else {
if (flag == false)
{
mask = 128 >> (i & 7);
vram[(i - z_buffer_offset)>>3] |= mask;
flag = true;
}
}
}
Est-ce plus optimisable ?
Pourrais-je obtenir un gain à l'écrire directement en assembleur ?
Oui, clairement tu disposes de plusieurs optimistions. Commencons par les choses faciles.
1. Si je me souviens bien, ton z-buffer est de 16 bits ? Dans ce cas, tu peux lire deux éléments d'un coup et faire un accès mémoire de moins tous les deux tours de boucle. Si tu unrolles ta boucle sur deux tours, ça se verra plus facilement.
2. Le test current == MAX_DEPTH_Z_BUFFER est probablement faux la plupart du temps, mieux vaut sauter dans ce cas rare et aller tout droit le reste du temps. En d'autres termes, inverser les branches du if/else.
Maintenant, des choses plus subtiles.
3. Tu peux considérer que les variables utilisées dans les deux branches de flag sont différentes. Dans ce cas, tu peux voir que tes masques subissent en fait une rotation d'un bit vers la droite à chaque tour. Tu pourrais effectuer la rotation à tous les tours et éviter le calcul de masque. [*1]
4. La même méthode peut être utilisée, plus trivialement, pour maintenir i - z_buffer_offset.
5. J'ai vraiment, vraiment envie d'écrire 128 >> ((i - flag) & 7) et (i - flag - z_buffer_offset) >> 3...
6. Tu ferais sans doute mieux d'accumuler tes mask dans un registre en local et d'envoyer tout ça dans la VRAM lorsque tu as rempli un octet. Surtout si tu parcours la VRAM dans l'ordre, auquel cas ces gros indices peuvent être remplacés par du vram[index++] = mask.
7. Si tu ne tiens pas trop à la structure de ligne/colonne, tu peux carrément les accumuler par paquets de 32 et les envoyer ensuite dans la VRAM une fois que tu atteins un alignement correct.
Pour des choses plus expérimentales...
8. Tu peux peut-être envisager de faire une passe uniquement pour les MAX_DEPTH_Z_BUFFER (quitte à stocker dans un nouveau tableau des informations sur quand flag change, par exemple) et ensuite faire une passe pour le reste des éléments.
J'aurais besoin de connaître plus de détails...
[*1] Quelle proportion du temps environ est-ce que les tests sur flag sont vrais ?
[*2] Est-il possible de reformuler ta boucle de façon à faire une écriture dans la vram à chaque tour de boucle ?
Franchement tu pourrais l'écrire en assembleur, si c'est critique alors gagner 10% à 20% de vitesse en vaudra la peine. Si tu as le temps avant de t'y mettre, j'aimerais en savoir plus sur les aspects dynamiques de ta fonction pour voir s'il n'y a pas de meilleurs angles d'approche.
Merci pour toutes ces pistes. Excuse moi c'est vrai je n'ai pas trop développé l'utilité du code.
Il s'agit d'un post traitement de mon image qui accentue les contrastes en les objets et "rien". Ce code sert à détecter les contours d'un objets, et dessiner un pixel noir SUR le bord de l'objet. Pour ça je parcours le z-buffer (tableau de short 128x64, initiallement rempli de MAX_DEPTH_Z_BUFFER = 0xffffff, dont la valeur change (forcement moins) si le pixel correspondant appartient à un objet
1. Lire z_buffer[i] renvoie un short, donc déjà 2 octets. Faire monter i de 2 à chaque tour de boucle ne fonctionne pas.
2. Comme tu as pu le deviner avec l'explication plus haut, c'est justement assez fréquent comme le z-buffer en est rempli. disons que c'est du 50/50.
3. Parce contre le changement de flag, c'est a dire quand on veut afficher un pixel noir, est très peu fréquent. Il vaut mieux privilégier une boucle principale très légère et allourdir dans la condition la plus profonde. Je vais tout de même tester
4. ok
5. Pourquoi pas De toute façon, flag est dans un registre, donc récupérer flag dans un registre ou 1 dans un autre ça ne change rien. Exact ?
1. Tu peux caster z_buffer en un pointeur sur int *, ensuite une fois sur deux tu lis un int. Ce tour-là tu prends ta valeur de z-buffer dans les octets hauts de l'int, au tour suivant tu prends les deux octets bas.
3. Si le changement de flag est très rare, alors tu as peut-être intérêt à mettre la boucle intérieure (qui dessine en noir) à l'intérieur de la boucle extérieure pour aller plus vite.
5. Exactement, c'est aussi ça l'intérêt. Si tu arrives à factoriser cette partie du code alors il y a des chances que tu puisses juste calculer les booléens mais ne pas effectuer le branchement if/else.
Une idée pour ma question [*2] ? C'est là que résident le plus de possibilités d'optim', essentiellement 3, 4, 5 et 6 en découlent assez bien.
Merci ! En effet, le rendu est vraiment mieux. En fait je suis preque obligé de mettre ce post traitement pour simplifier les textures. Je developperai avec des exemples avant/après à un autre moment Seulement je perds entre 5 et 15% de fps...
J'ai fais avec un accès à la vram par octet entier, c'est moins performant. De pas beaucoup mais moins performant qand même : 24 à 23fps
bool flag = false;
char i_mod_8;
for (int i = 0; i<z_buffer_size; i++)
{
i_mod_8 = i & 7;
current = z_buffer[i];
if (current == MAX_DEPTH_Z_BUFFER)
{
if (flag == true)
{
mask |= 128 >> i_mod_8;//((i-1) & 7);
flag = false;
}
} else {
if (flag == false)
{
mask |= 128 >> i_mod_8;
flag = true;
}
}
if (i_mod_8 == 7)
{ //if (mask > 0)
vram[i>>3] |= mask;
mask = 0;
}
}
Je pense que ça vient principalement du fait le nombre d'accès à la vram est trop faible. Et du coup le gain est annulé par le calul de i_mod_8 et la condition supplémentaire.
J'ai fait le calcul, pour ma vue actuelle, on ecrit environ 100 pixel noirs pour 128*64 pixels. Soit 1,3% du temps.
1. Ok mais je vois pas à quoi ça pourrait servir
3. Pas compris
5. Ok je vais réflechir à cette piste
[2]. Oui c'est bien possible. C'est que l'on risque d'écrire de nombreux 00000000 dans la vram. mais s'il y a un gain, on s'en fiche. La logique de l'ago en fait c'est. Je parcours tout le z_buffer, dès qu'il y a un changement de valeur (MAX_DETPH_Z_BUFFER ou pas) je dessine un pixel noir au même endroit dans la vram).
Ajouté le 11/12/2018 à 23:57 :
J'ai eu une superbe idée !
J'ai vraiment accéleré l'algo. L'idée :
Je parcours le tableau de 2 en 2, et si je detecte un changement je vérifie l'état du pixel juste à gauche. Ça divise presque par deux le temps de l'algo. Ça laisse quelques cas particulier, notamment si j'ai un objet de 1px de largeur sur un x impaire, je vais pas le détecter. Mais bon, le rsique est très faible, sachant que ce pixel est peut être déjà noir en plus du fait de l'objet lui-même.
Bingo !
bool flag = false;
for (int i = 0; i<z_buffer_size; i+=2)
{
current = z_buffer[i];
if (current == MAX_DEPTH_Z_BUFFER)
{
if (flag == true)
{
if (z_buffer[i-1] == MAX_DEPTH_Z_BUFFER)
{ // il y avait rien juste a gauche
mask = 128 >> ((i-2) & 7);
vram[(i - 2 - z_buffer_offset)>>3] |= mask;
flag = false;
} else { // l objet commencait en fait 1 pixel a gauche
mask = 128 >> ((i-1) & 7);
vram[(i - 1 - z_buffer_offset)>>3] |= mask;
flag = false;
}
}
} else {
if (flag == false)
{
if (z_buffer[i-1] == MAX_DEPTH_Z_BUFFER)
{ // il y avait rien juste a gauche
mask = 128 >> (i & 7);
vram[(i - z_buffer_offset)>>3] |= mask;
flag = true;
} else { // l objet commencait en fait 1 pixel a gauche
mask = 128 >> ((i-1) & 7);
vram[(i - 1 - z_buffer_offset)>>3] |= mask;
flag = true;
}
}
}
}
Peut-être quelques ajustements, mais l'idée est là
Planète Casio est un site communautaire non affilié à Casio. Toute reproduction de Planète Casio, même partielle, est interdite.
Les programmes et autres publications présentes sur Planète Casio restent la propriété de leurs auteurs et peuvent être soumis à des licences ou copyrights.
CASIO est une marque déposée par CASIO Computer Co., Ltd


 )
) )
) J'ai encore optimisé mon algorithme pour appliquer les textures, j'étais passé à côté de quelque chose d'énorme, résultat j'ai pu simplifier encore mes calculs pour gagner 35% de performances. Je suis passé de 10 décalages de bit, 17 mults, 9 additions à 7 décalages, 12 mults et 10 additions.
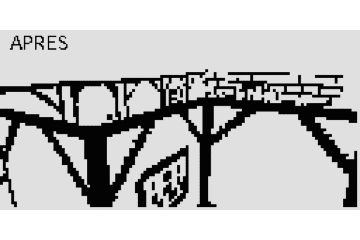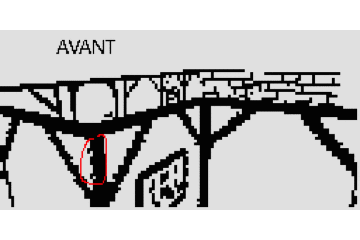
J'ai encore optimisé mon algorithme pour appliquer les textures, j'étais passé à côté de quelque chose d'énorme, résultat j'ai pu simplifier encore mes calculs pour gagner 35% de performances. Je suis passé de 10 décalages de bit, 17 mults, 9 additions à 7 décalages, 12 mults et 10 additions. Ici on voit la texture blanche qui passe par dessus le mur de brique (frame 2 à 7)
Ici on voit la texture blanche qui passe par dessus le mur de brique (frame 2 à 7)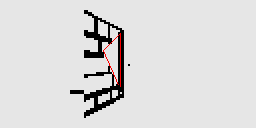


 Ajouté une ligne d'horizon (c'est tout bête mais ça rend bien mieux)
Ajouté une ligne d'horizon (c'est tout bête mais ça rend bien mieux)


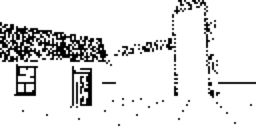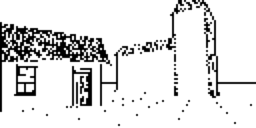

 Il reste néanmoins quelques petits bugs d'affichage avec cette méthode, mais elle fonctionne 90% du temps.
Il reste néanmoins quelques petits bugs d'affichage avec cette méthode, mais elle fonctionne 90% du temps.
Citer : Posté le 11/12/2018 14:56 | #
Peux-tu me dire ce qu'est le DMA ?
Citer : Posté le 11/12/2018 18:02 | #
@ Lephe : le Doom sur graph 90 est en raycasting non ?
Citer : Posté le 11/12/2018 18:30 | #
@lightmare le doom dont tu parle est effectivement en raycasting mais il n'est pas encore compatible g90 et n'est donc jouable que sur cg-10/20
sinon il y a wolfenstein3D sur g75 qui utilise cette technologie
Citer : Posté le 11/12/2018 19:05 | #
Oui bien sûr, le DMA (Direct Memory Access [Controller]) c'est un composant électronique qui est capable de transférer des données à l'intérieur de la calculatrice pendant que le processeur fait autre chose.
Ici, ce qui nous intéresse c'est d'envoyer les données graphiques de la mémoire à l'écran, et sur Graph 90 c'est le facteur de performance numéro 1 quand on fait quoi que ce soit en temps réel.
En effet, si le processeur doit faire le transfert de la mémoire à l'écran lui-même, le temps de transfert est si long qu'on ne peut même pas tenir 20 FPS, et je ne parle même pas de dessiner les frames.
Par contre, si le DMA fait le transfert, non seulement c'est plus rapide mais en plus le processeur peut dessiner le frame suivant pendant ce temps. Cela permet d'atteindre des fréquences d'affichage raisonnables.
Citer : Posté le 11/12/2018 19:15 | #
Et la graph 90 l'utilise automatiquement ou il faut le parametrer ?
Citer : Posté le 11/12/2018 19:16 | #
Il faut le paramétrer, c'est un poil technique mais c'est faisable. @Nemhardy s'en est déjà servi, il me semble.
Dans tous les cas, utiliser ou non le DMA ne change pas le reste de ton programme, donc tu peux toujours programmer ton rendu et te soucier ensuite de comment tu l'affiches. Utiliser Bdisp_PutDisp_DD() est suffisant pour un début.
Es-tu bien familier avec le C/C++ ou autre langage que tu comptes utiliser ?
Citer : Posté le 11/12/2018 19:21 | #
Euhhh...
Pas vraiment je connais seulement les bases (variables, calculs, boucles)
Mais je suis prets à apprendre
Ajouté le 11/12/2018 à 19:22 :
Et je maitrise déjà bien le basique qui en est assez proche si je ne me trompe pas ?
Citer : Posté le 11/12/2018 19:24 | #
Ça dépend, tu veux la pilule rouge ou la pillule bleu ??
Citer : Posté le 11/12/2018 19:25 | #
Pas d'inquiétude, tu peux y aller sans te poser trop de questions tant que tu fais attention à bien comprendre quand tu rencontres des erreurs !
Et je maitrise déjà bien le basique qui en est assez proche si je ne me trompe pas ?
Il n'y a pas beaucoup de points communs en fait, à part le fait qu'il y a des variables, des conditions et des boucles ce n'est pas le même genre de langages !
Citer : Posté le 11/12/2018 19:26 | #
La bleu correspond à quoi
Citer : Posté le 11/12/2018 19:28 | #
À te laisser continuer ta vie dans ce rêve illusoire qu'est le tiens
Citer : Posté le 11/12/2018 19:29 | #
Ah...
La rouge, montre moi la vérité
Citer : Posté le 11/12/2018 19:31 | #
Tu es sûr ? La vérité est bourrée de détails de bas niveau...
Citer : Posté le 11/12/2018 19:58 | #
Où pourrais-je trover toutes les fonctions C spécifiques à la programmation pour casio ?
Citer : Posté le 11/12/2018 20:06 | #
Commence par ce tutoriel pour avoir les infos « méta » sur le développement sur Prizm ; ensuite la référence ultime est le WikiPrizm de Cemetech.
Citer : Posté le 11/12/2018 20:29 | #
Je sens que je vais moins m'ennuyer au CDI
Citer : Posté le 11/12/2018 21:44 | #
Merci pour avoir partager tes impressions ici Leno. En effet je me suis grandement basé sur le site ScratchAPixel. Mais d'autres sites vulgarisent davantage.
Sinon, retour aux choses sérieuses !
J'ai besoin d'optimiser à fond quelques lignes de code :
for (int i = 0; i<z_buffer_size; i++)
{
current = z_buffer[i];
if (current == MAX_DEPTH_Z_BUFFER)
{
if (flag == true)
{
mask = 128 >> ((i-1) & 7);
vram[(i - 1 - z_buffer_offset)>>3] |= mask;
flag = false;
}
} else {
if (flag == false)
{
mask = 128 >> (i & 7);
vram[(i - z_buffer_offset)>>3] |= mask;
flag = true;
}
}
}
Pourrais-je obtenir un gain à l'écrire directement en assembleur ?
Citer : Posté le 11/12/2018 21:58 | #
Oui, clairement tu disposes de plusieurs optimistions. Commencons par les choses faciles.
1. Si je me souviens bien, ton z-buffer est de 16 bits ? Dans ce cas, tu peux lire deux éléments d'un coup et faire un accès mémoire de moins tous les deux tours de boucle. Si tu unrolles ta boucle sur deux tours, ça se verra plus facilement.
2. Le test current == MAX_DEPTH_Z_BUFFER est probablement faux la plupart du temps, mieux vaut sauter dans ce cas rare et aller tout droit le reste du temps. En d'autres termes, inverser les branches du if/else.
Maintenant, des choses plus subtiles.
3. Tu peux considérer que les variables utilisées dans les deux branches de flag sont différentes. Dans ce cas, tu peux voir que tes masques subissent en fait une rotation d'un bit vers la droite à chaque tour. Tu pourrais effectuer la rotation à tous les tours et éviter le calcul de masque. [*1]
4. La même méthode peut être utilisée, plus trivialement, pour maintenir i - z_buffer_offset.
5. J'ai vraiment, vraiment envie d'écrire 128 >> ((i - flag) & 7) et (i - flag - z_buffer_offset) >> 3...
6. Tu ferais sans doute mieux d'accumuler tes mask dans un registre en local et d'envoyer tout ça dans la VRAM lorsque tu as rempli un octet. Surtout si tu parcours la VRAM dans l'ordre, auquel cas ces gros indices peuvent être remplacés par du vram[index++] = mask.
7. Si tu ne tiens pas trop à la structure de ligne/colonne, tu peux carrément les accumuler par paquets de 32 et les envoyer ensuite dans la VRAM une fois que tu atteins un alignement correct.
Pour des choses plus expérimentales...
8. Tu peux peut-être envisager de faire une passe uniquement pour les MAX_DEPTH_Z_BUFFER (quitte à stocker dans un nouveau tableau des informations sur quand flag change, par exemple) et ensuite faire une passe pour le reste des éléments.
J'aurais besoin de connaître plus de détails...
[*1] Quelle proportion du temps environ est-ce que les tests sur flag sont vrais ?
[*2] Est-il possible de reformuler ta boucle de façon à faire une écriture dans la vram à chaque tour de boucle ?
Franchement tu pourrais l'écrire en assembleur, si c'est critique alors gagner 10% à 20% de vitesse en vaudra la peine. Si tu as le temps avant de t'y mettre, j'aimerais en savoir plus sur les aspects dynamiques de ta fonction pour voir s'il n'y a pas de meilleurs angles d'approche.
Citer : Posté le 11/12/2018 22:26 | #
Merci pour toutes ces pistes. Excuse moi c'est vrai je n'ai pas trop développé l'utilité du code.
Il s'agit d'un post traitement de mon image qui accentue les contrastes en les objets et "rien". Ce code sert à détecter les contours d'un objets, et dessiner un pixel noir SUR le bord de l'objet. Pour ça je parcours le z-buffer (tableau de short 128x64, initiallement rempli de MAX_DEPTH_Z_BUFFER = 0xffffff, dont la valeur change (forcement moins) si le pixel correspondant appartient à un objet
1. Lire z_buffer[i] renvoie un short, donc déjà 2 octets. Faire monter i de 2 à chaque tour de boucle ne fonctionne pas.
2. Comme tu as pu le deviner avec l'explication plus haut, c'est justement assez fréquent comme le z-buffer en est rempli. disons que c'est du 50/50.
3. Parce contre le changement de flag, c'est a dire quand on veut afficher un pixel noir, est très peu fréquent. Il vaut mieux privilégier une boucle principale très légère et allourdir dans la condition la plus profonde. Je vais tout de même tester
4. ok
5. Pourquoi pas
6. Très bonne piste, merci j'essaye ça.
7. Pareil dans un second temps
8. Ok je note
Merci à toi !
Citer : Posté le 11/12/2018 22:35 | #
Alright, c'est intelligent comme transformation !
1. Tu peux caster z_buffer en un pointeur sur int *, ensuite une fois sur deux tu lis un int. Ce tour-là tu prends ta valeur de z-buffer dans les octets hauts de l'int, au tour suivant tu prends les deux octets bas.
3. Si le changement de flag est très rare, alors tu as peut-être intérêt à mettre la boucle intérieure (qui dessine en noir) à l'intérieur de la boucle extérieure pour aller plus vite.
5. Exactement, c'est aussi ça l'intérêt. Si tu arrives à factoriser cette partie du code alors il y a des chances que tu puisses juste calculer les booléens mais ne pas effectuer le branchement if/else.
Une idée pour ma question [*2] ? C'est là que résident le plus de possibilités d'optim', essentiellement 3, 4, 5 et 6 en découlent assez bien.
Citer : Posté le 11/12/2018 23:25 | #
Merci ! En effet, le rendu est vraiment mieux. En fait je suis preque obligé de mettre ce post traitement pour simplifier les textures. Je developperai avec des exemples avant/après à un autre moment
J'ai fais avec un accès à la vram par octet entier, c'est moins performant. De pas beaucoup mais moins performant qand même : 24 à 23fps
char i_mod_8;
for (int i = 0; i<z_buffer_size; i++)
{
i_mod_8 = i & 7;
current = z_buffer[i];
if (current == MAX_DEPTH_Z_BUFFER)
{
if (flag == true)
{
mask |= 128 >> i_mod_8;//((i-1) & 7);
flag = false;
}
} else {
if (flag == false)
{
mask |= 128 >> i_mod_8;
flag = true;
}
}
if (i_mod_8 == 7)
{
//if (mask > 0)
vram[i>>3] |= mask;
mask = 0;
}
}
J'ai fait le calcul, pour ma vue actuelle, on ecrit environ 100 pixel noirs pour 128*64 pixels. Soit 1,3% du temps.
1. Ok mais je vois pas à quoi ça pourrait servir
3. Pas compris
5. Ok je vais réflechir à cette piste
[2]. Oui c'est bien possible. C'est que l'on risque d'écrire de nombreux 00000000 dans la vram. mais s'il y a un gain, on s'en fiche. La logique de l'ago en fait c'est. Je parcours tout le z_buffer, dès qu'il y a un changement de valeur (MAX_DETPH_Z_BUFFER ou pas) je dessine un pixel noir au même endroit dans la vram).
Ajouté le 11/12/2018 à 23:57 :
J'ai eu une superbe idée !
J'ai vraiment accéleré l'algo. L'idée :
Je parcours le tableau de 2 en 2, et si je detecte un changement je vérifie l'état du pixel juste à gauche. Ça divise presque par deux le temps de l'algo. Ça laisse quelques cas particulier, notamment si j'ai un objet de 1px de largeur sur un x impaire, je vais pas le détecter. Mais bon, le rsique est très faible, sachant que ce pixel est peut être déjà noir en plus du fait de l'objet lui-même.
Bingo !
for (int i = 0; i<z_buffer_size; i+=2)
{
current = z_buffer[i];
if (current == MAX_DEPTH_Z_BUFFER)
{
if (flag == true)
{
if (z_buffer[i-1] == MAX_DEPTH_Z_BUFFER)
{
// il y avait rien juste a gauche
mask = 128 >> ((i-2) & 7);
vram[(i - 2 - z_buffer_offset)>>3] |= mask;
flag = false;
} else {
// l objet commencait en fait 1 pixel a gauche
mask = 128 >> ((i-1) & 7);
vram[(i - 1 - z_buffer_offset)>>3] |= mask;
flag = false;
}
}
} else {
if (flag == false)
{
if (z_buffer[i-1] == MAX_DEPTH_Z_BUFFER)
{
// il y avait rien juste a gauche
mask = 128 >> (i & 7);
vram[(i - z_buffer_offset)>>3] |= mask;
flag = true;
} else {
// l objet commencait en fait 1 pixel a gauche
mask = 128 >> ((i-1) & 7);
vram[(i - 1 - z_buffer_offset)>>3] |= mask;
flag = true;
}
}
}
}